第5章Scrapy 框架
视频学习
scrapy环境简介视频
http://home.hddly.cn:50090/media/chrome_IWlr5MZVSJ.mp4
创建scrapy项目视频
http://home.hddly.cn:50090/media/chrome_oOCFZ6Y8IT.mp4
在云课上完成scrapy用户采集
http://home.hddly.cn:50090/media/TiSsnUj7Xt.mp4
在本地上完成scrapy用户采集
http://home.hddly.cn:50090/media/yC4w8sHV4d.mp4
5.1 Scrapy 框架的介绍和安装
【练一练】Scrapy 爬虫框架简介与基本操作
下面我们使用 scrapy 写一个爬虫脚本,爬取蓝桥课程页面所有课程名称、简介、类型和学习人数信息,并保存为 JSON 文本。课程页面的地址是 https://www.lanqiao.cn/courses/。
在 /home/shiyanlou/Code 下新建 shiyanlou_courses_spider.py 文件,写入 Scrapy 爬虫的基本结构:
xxxxxxxxxx291import scrapy2
3
4class ShiyanlouCoursesSpider(scrapy.Spider):5 """6 使用 scrapy 爬取页面数据需要编写一个爬虫类,该爬虫类要继承 scrapy.Spider 类7 在爬虫类中定义要请求的网站和链接、如何从返回的网页提取数据等等8 在 scrapy 项目中可能会有多个爬虫,name 属性用于标识每个爬虫,各个爬虫类的 name 值不能相同9 """10 name = 'shiyanlou-courses'11
12 # 注意此方法的方法名字是固定的,不可更改13 def start_requests(self):14 """15 此方法需要返回一个可迭代对象,迭代的元素是 scrapy.Request 对象16 可迭代对象可以是一个列表或者迭代器,这样 scrapy 就知道有哪些网页需要爬取了17 scrapy.Request 接受一个 url 参数和一个 callback 参数18 url 指明要爬取的网页19 callback 是一个回调函数,用于处理返回的网页,它的值通常是一个提取数据的 parse 方法20 """21
22 # 注意此方法的方法名字也是固定的,不可更改23 def parse(self, response):24 """25 这个方法作为 scrapy.Request 的 callback ,在里面编写提取数据的代码26 scrapy 中的下载器会下载 start_reqeusts 中定义的每个 Request27 并且将结果封装为一个 response 对象传入这个方法28 """29 pass分析蓝桥的课程页面可以看出,每页有 4 x 5 行共 20 个课程卡片,我们需要从中提取 20 条数据,爬取前 3 页,共计 60 条数据,点击页面底部的「下一页」按钮进入下一页,将浏览器地址栏中的地址复制出来:
这样就可以写出 start_requests 方法:
xxxxxxxxxx81def start_requests(self):2 # 课程列表页面 URL ,注意此列表中的地址可能有变动,需手动打开页面复制最新地址3 url_list = ['https://www.lanqiao.cn/courses/',4 'https://www.lanqiao.cn/courses/?page=2',5 'https://www.lanqiao.cn/courses/?page=3']6 # 返回一个生成器,生成 Request 对象,生成器是可迭代对象7 for url in url_list:8 yield scrapy.Request(url=url, callback=self.parse)Scrapy 内部的下载器会下载每个 Request,然后将结果封装为 response 对象传入 parse 方法,这个对象和前面 scrapy shell 练习中的对象是一样的,也就是说你可以用 response.css() 或者 response.xpath() 来提取数据了。
通过分析蓝桥课程页面的文档结构,以《Linux 入门基础(新版)》课程为例,我们需要提取的数据主要包含在下面的 div 里面:
根据这个 div 可以用提取器写出 parse 方法:
xxxxxxxxxx161def parse(self, response):2 # 遍历每个课程的 div.col-md-33 for course in response.css('div.col-md-3'):4 # 使用 css 语法对每个 course 提取数据5 yield {6 # 课程名称,注意这里使用 strip 方法去掉字符串前后的空白字符7 # 所谓空白字符,指的是空格、换行符、制表符8 # 下面获取 name 的写法还可以省略 h6 的类属性,思考一下为什么可以省略9 'name': course.css('h6.course-name::text').extract_first().strip(),10 # 课程描述11 'description': course.css('div.course-description::text').extract_first().strip(),12 # 课程类型13 'type': course.css('span.course-type::text').extract_first('免费').strip(),14 # 学生人数15 'students': course.css('span.students-count span::text').extract_first()16 }完整源码
xxxxxxxxxx411import scrapy2class ShiyanlouCoursesSpider(scrapy.Spider):5"""6使用 scrapy 爬取页面数据需要编写一个爬虫类,该爬虫类要继承 scrapy.Spider 类7在爬虫类中定义要请求的网站和链接、如何从返回的网页提取数据等等8在 scrapy 项目中可能会有多个爬虫,name 属性用于标识每个爬虫,各个爬虫类的 name 值不能相同9"""10name = 'shiyanlou-courses'11# 注意此方法的方法名字是固定的,不可更改13def start_requests(self):14# 课程列表页面 URL ,注意此列表中的地址可能有变动,需手动打开页面复制最新地址15url_list = ['https://www.lanqiao.cn/courses/',16'https://www.lanqiao.cn/courses/?page=2',17'https://www.lanqiao.cn/courses/?page=3']18# 返回一个生成器,生成 Request 对象,生成器是可迭代对象19for url in url_list:20yield scrapy.Request(url=url, callback=self.parse)21# 注意此方法的方法名字也是固定的,不可更改24def parse(self, response):25# 遍历每个课程的 div.col-md-326for course in response.css('div.col-md-3'):27# 使用 css 语法对每个 course 提取数据28yield {29# 课程名称,注意这里使用 strip 方法去掉字符串前后的空白字符30# 所谓空白字符,指的是空格、换行符、制表符31# 下面获取 name 的写法还可以省略 h6 的类属性,思考一下为什么可以省略32'name': course.css('h6.course-name::text').extract_first().strip(),33# 课程描述34'description': course.css('div.course-description::text').extract_first().strip(),35# 课程类型36'type': course.css('span.course-type::text').extract_first('免费').strip(),37# 学生人数38'students': course.css('span.students-count span::text').extract_first()39}40
运行
按照上一步中的格式写好 spider 后,就能使用 scrapy 的 runspider 命令来运行爬虫了。
xxxxxxxxxx31cd /home/shiyanlou/Code2pip install scrapy3scrapy runspider shiyanlou_courses_spider.py -o data.json注意这里输出得到的 data.json 文件中的中文显示成 unicode 编码的形式,所以看到感觉像是乱码,其实是正常的。
-o 参数表示打开一个文件,scrapy 默认会将结果序列化为 JSON 格式写入其中。爬虫运行完后,在当前目录打开 data.json 文件就能看到爬取到的数据了。
5.2 连接数据库的标准 Scrapy 项目
【练一练】连接数据库的标准 Scrapy 项目
介绍
上一节中,我们只是基于 Scrapy 写了一个爬虫脚本,并没有使用 Scrapy 项目标准的形式。这一节我们要将脚本变成标准 Scrapy 项目的形式,并将爬取到的数据存储到 MySQL 数据库中。数据库的连接和操作使用 SQLAlchemy。
知识点
- 连接数据库
- 创建 Scrapy 项目
- 创建爬虫
- Item 容器
- Item Pipeline
- Models 创建表
- 保存 Item 到数据库
- Item 过滤
连接数据库准备
本实验会将爬取的数据存入 MySQL,需要做一些准备工作。首先需要将 MySQL 的编码格式设置为 utf8,编辑配置文件:
xxxxxxxxxx11sudo vim /etc/mysql/my.cnf检查以下几个配置是否存在,有的话则可以不修改:
xxxxxxxxxx81[client]2default-character-set = utf83
4[mysqld]5character-set-server = utf86
7[mysql]8default-character-set = utf8保存后,就可以启动 mysql 了:
xxxxxxxxxx11sudo service mysql start以 root 身份进入 mysql,实验环境默认是没有密码的:
xxxxxxxxxx11mysql -uroot创建 shiyanlou 库给本实验使用:
xxxxxxxxxx11mysql > CREATE DATABASE shiyanlou;完成后输入 quit 退出。
本实验使用 SQLAlchemy 这个 ORM 在爬虫程序中连接和操作 MySQL ,先安装一下sqlalchemy,还需要安装 Python3 连接 MySQL 的驱动程序 mysqlclient:
xxxxxxxxxx41pip install scrapy2pip install sqlalchemy3sudo apt-get install libmysqlclient-dev4pip install mysqlclient
创建项目
进入到 /home/shiyanlou/Code 目录,使用 Scrapy 提供的 startproject 命令创建一个 Scrapy 项目,需要提供一个项目名称,我们要爬取蓝桥的数据,所以将 shiyanlou 作为项目名:
xxxxxxxxxx21cd /home/shiyanlou/Code2scrapy startproject shiyanlou进入 /home/shiyanlou/Code/shiyanlou 目录,可以看到项目结构是这样的:
xxxxxxxxxx91shiyanlou/2 scrapy.cfg # 部署配置文件3 shiyanlou/ # 项目名称4 __init__.py5 items.py # 项目 items 定义在这里6 pipelines.py # 项目 pipelines 定义在这里7 settings.py # 项目配置文件8 spiders/ # 所有爬虫写在这个目录下面9 __init__.py创建爬虫
Scrapy 的 genspider 命令可以快速初始化一个爬虫模版,使用方法如下:
xxxxxxxxxx11scrapy genspider <name> <domain>其中 name 参数是这个爬虫的名称,domain 指定要爬取的网站。
进入第二个 shiyanlou 目录,运行下面的命令快速初始化一个爬虫模版:
xxxxxxxxxx21cd /home/shiyanlou/Code/shiyanlou/shiyanlou2scrapy genspider courses lanqiao.cnScrapy 会在 /home/shiyanlou/Code/shiyanlou/shiyanlou/spiders 目录下新建一个 courses.py 文件,并且在文件中初始化了代码结构:
xxxxxxxxxx101import scrapy2
3
4class CoursesSpider(scrapy.Spider):5 name = 'courses'6 allowed_domains = ['lanqiao.cn']7 start_urls = ['http://lanqiao.cn/']8
9 def parse(self, response):10 pass这里面有一个新的属性 allowed_domains 是在前一节中没有介绍到的。它是干嘛的呢?allow_domains 的值可以是一个列表或字符串,包含这个爬虫可以爬取的域名。假设我们要爬的页面是 https://www.example.com/1.html ,那么就把 example.com 添加到 allowed_domains。这个属性是可选的,在我们的项目中并不需要使用它,可以删除。
除此之外 start_urls 的代码和上一节相同:
xxxxxxxxxx131# -*- coding: utf-8 -*-2import scrapy3
4
5class CoursesSpider(scrapy.Spider):6 name = 'courses'7
8 9 def start_urls(self):10 url_list = ['https://www.lanqiao.cn/courses/',11 'https://www.lanqiao.cn/courses/?page=2',12 'https://www.lanqiao.cn/courses/?page=3']13 return url_list
Item
爬虫的主要目标是从网页中提取结构化的信息,Scrapy 爬虫可以将爬取到的数据作为一个 Python dict 返回,但由于 dict 的无序性,所以它不太适合存放结构性数据。Scrapy 推荐使用 Item 容器来存放爬取到的数据。
所有的 items 写在 items.py(/home/shiyanlou/Code/shiyanlou/shiyanlou/items.py) 中,下面为要爬取的课程定义一个 Item:
xxxxxxxxxx121import scrapy2
3
4class CourseItem(scrapy.Item):5 """6 定义 Item 非常简单,只需要继承 scrapy.Item 类,将每个要爬取的数据声明为 scrapy.Field()7 下面的代码是我们每个课程要爬取的 4 个数据8 """9 name = scrapy.Field()10 description = scrapy.Field()11 type = scrapy.Field()12 students = scrapy.Field()有了 CourseItem,就可以将 parse 方法的返回包装成它:
xxxxxxxxxx251# -*- coding: utf-8 -*-2import scrapy3from shiyanlou.items import CourseItem4
5
6class CoursesSpider(scrapy.Spider):7 name = 'courses'8
9 10 def start_urls(self):11 url_list = ['https://www.lanqiao.cn/courses/',12 'https://www.lanqiao.cn/courses/?page=2',13 'https://www.lanqiao.cn/courses/?page=3']14 return url_list15
16 def parse(self, response):17 for course in response.css('div.col-md-3'):18 # 将返回结果包装为 CourseItem ,其它地方同上一节19 item = CourseItem({20 'name': course.css('h6::text').extract_first().strip(),21 'description': course.css('div.course-description::text').extract_first().strip(),22 'type': course.css('span.course-type::text').extract_first('免费').strip(),23 'students': course.css('span.students-count span::text').extract_first()24 })25 yield item
Item Pipeline
如果把 scrapy 想象成一个产品线,spider 负责从网页上爬取数据,Item 相当于一个包装盒,对爬取的数据进行标准化包装,然后把它们扔到 Pipeline 流水线中。
主要在 Pipeline 对 Item 进行这几项处理:
- 验证爬取到的数据(检查 item 是否有特定的 field )
- 检查数据是否重复
- 存储到数据库
当创建项目时,scrapy 已经在 /home/shiyanlou/Code/shiyanlou/shiyanlou/pipelines.py 中为项目生成了一个 pipline 模版:
xxxxxxxxxx61class ShiyanlouPipeline(object):2 def process_item(self, item, spider):3 """ parse 出来的 item 会被传入这里,这里编写的处理代码会4 作用到每一个 item 上面。这个方法必须要返回一个 item 对象。5 """6 return item除了 process_item 还有两个常用的 hooks 方法,open_spider 和 close_spider:
xxxxxxxxxx131class ShiyanlouPipeline(object):2 def process_item(self, item, spider):3 return item4
5 def open_spider(self, spider):6 """ 当爬虫被开启的时候调用7 """8 pass9
10 def close_spider(self, spider):11 """ 当爬虫被关闭的时候调用12 """13 pass定义 Model,创建表
在 items.py 所在目录下创建 models.py(/home/shiyanlou/Code/shiyanlou/shiyanlou/models.py),在里面使用 SQLAlchemy 语法定义 courses 表结构:
创建文件
xxxxxxxxxx21cd /home/shiyanlou/Code/shiyanlou/shiyanlou2touch ./models.py
源码
xxxxxxxxxx191from sqlalchemy import create_engine2from sqlalchemy.ext.declarative import declarative_base3from sqlalchemy import Column, String, Integer4
5
6engine = create_engine('mysql://root@localhost:3306/shiyanlou?charset=utf8')7Base = declarative_base()8
9class Course(Base):10 __tablename__ = 'courses'11
12 id = Column(Integer, primary_key=True)13 name = Column(String(64), index=True)14 description = Column(String(1024))15 type = Column(String(64), index=True)16 students = Column(Integer)17
18if __name__ == '__main__':19 Base.metadata.create_all(engine)使用 SQLAlchemy 创建映射类 Course 这步操作在前面的实验《关系数据库 MySQL 和 ORM》中讲到了,大家可以去查阅相关文档,也可以通过《SQLAlchemy 基础教程》 了解更多相关知识。
运行程序:
xxxxxxxxxx11python3 models.py如果运行正确的话,程序什么都不会输出,执行完后,进入 MySQL 客户端中检查是否已经创建了表:
xxxxxxxxxx81use shiyanlou;2show tables;3desc courses;4+---------------------+5| Tables_in_shiyanlou |6+---------------------+7| courses |8+---------------------+如果出现类似上面的东西说明表已经创建成功了!
注意,如果遇到 MySQLdb 包没有找到的错误,有以下几种可能,依次排查下就可以了:
- mysqlclient 没有安装
- mysqlclient 被 sudo pip3 install 安装到了系统路径,但在 virtualenv 里执行的 scrapy 没有找到这个包
- mysqlclient 被 pip3 install 安装到了 virtualenv,但没有激活 virtualenv 执行的 scrapy 没有找到这个包
- mysqlclient 被 pip3 install 安装到了 virtualenv,但没有在 virtualenv 安装 scrapy,执行 scrapy 的时候用的是系统的 scrapy(which scrapy 可以查看执行的路径)
- mysqlclient 和 scrapy 被 pip3 install 安装到了 virtualenv,但安装完成后没有 deactivate 再次重新激活 virtualenv,执行 scrapy 的时候用的是系统的 scrapy(which scrapy 可以查看执行的路径
保存 item 到数据库
创建好数据表后,就可以在 pipelines.py 编写代码将爬取到的每个 item 存入数据库中。
xxxxxxxxxx301from sqlalchemy.orm import sessionmaker2from shiyanlou.models import Course, engine3
4
5class ShiyanlouPipeline(object):6
7 def process_item(self, item, spider):8 # 提取的学习人数是字符串,把它转换成 int9 item['students'] = int(item['students'])10 # 根据 item 创建 Course Model 对象并添加到 session11 # item 可以当成字典来用,所以也可以使用字典解构, 相当于12 # Course(13 # name=item['name'],14 # type=item['type'],15 # ...,16 # )17 self.session.add(Course(**item))18 return item19
20 def open_spider(self, spider):21 """ 在爬虫被开启的时候,创建数据库 session22 """23 Session = sessionmaker(bind=engine)24 self.session = Session()25
26 def close_spider(self, spider):27 """ 爬虫关闭后,提交 session 然后关闭 session28 """29 self.session.commit()30 self.session.close()我们编写的这个 ShiyanlouPipeline 默认是关闭的状态,要开启它,需要在 /home/shiyanlou/Code/shiyanlou/shiyanlou/settings.py 将下面的代码取消注释:
xxxxxxxxxx41# 默认是被注释的2ITEM_PIPELINES = {3 'shiyanlou.pipelines.ShiyanlouPipeline': 3004}ITEM_PIPELINES 里面配置需要开启的 pipeline,它是一个字典,key 表示 pipeline 的位置,值是一个数字,表示的是当开启多个 pipeline 时它的执行顺序,值小的先执行,这个值通常设在 100~1000 之间
运行
前面使用的 runspider 命令用于启动一个独立的 scrapy 爬虫脚本,在 scrapy 项目中启动爬虫使用 crawl 命令,需要指定爬虫的 name:
xxxxxxxxxx21cd /home/shiyanlou/Code/shiyanlou/shiyanlou2scrapy crawl courses爬虫运行完后,进入 MySQL,输入下面的命令查看爬取数据的前 3 个:
xxxxxxxxxx21mysql> use shiyanlou;2mysql> select name, type, description, students from courses limit 3\G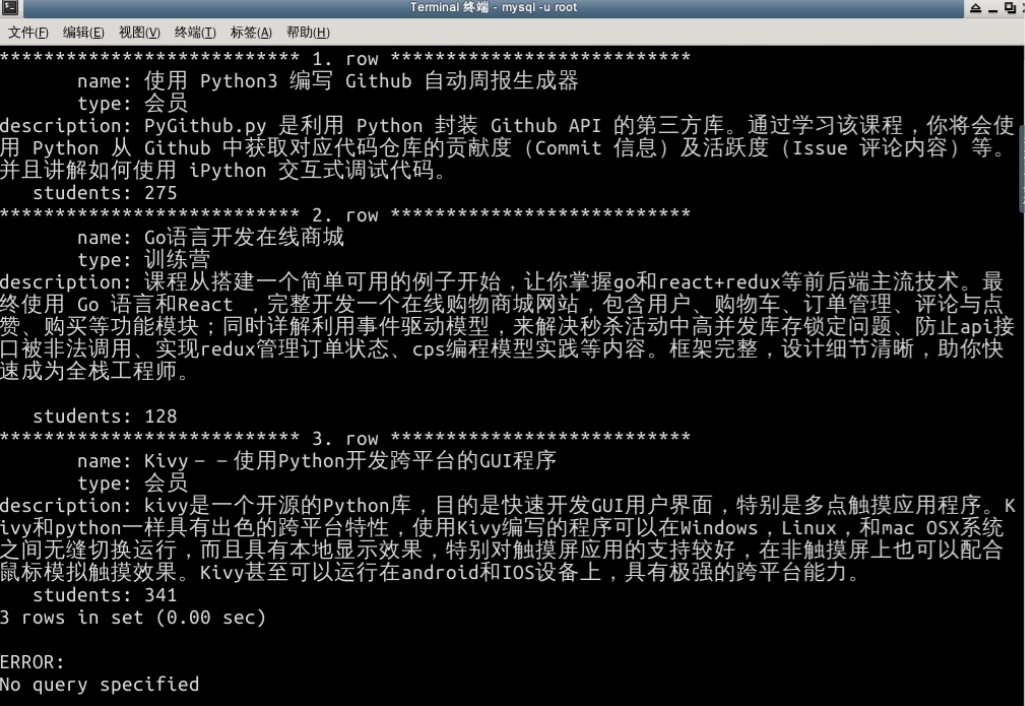
因为 Scrapy 爬虫是异步执行的,所以爬取到的 course 顺序和蓝桥网站上的会不一样
随堂练习截图
在云课中完成《连接数据库的标准 Scrapy 项目》,然后截图。截图中包含cources.py脚本,items.py脚本,和item pipline脚本,运行脚本和mysql查询数据脚本
5.3 Scrapy 爬取蓝桥用户数据
【练一练】Scrapy 爬取蓝桥用户数据
简介
本节内容运用前两节学到的知识,爬取蓝桥的用户数据,主要是为了练习、巩固前面学习到的知识。
知识点
- Scrapy 项目框架
- 分析网页元素字段
- SQLAlchemy 定义数据模型
- 创建 Item
- 解析数据
要爬取的内容
下面是一个用户主页的截图,箭头指的是我们要爬取的内容:
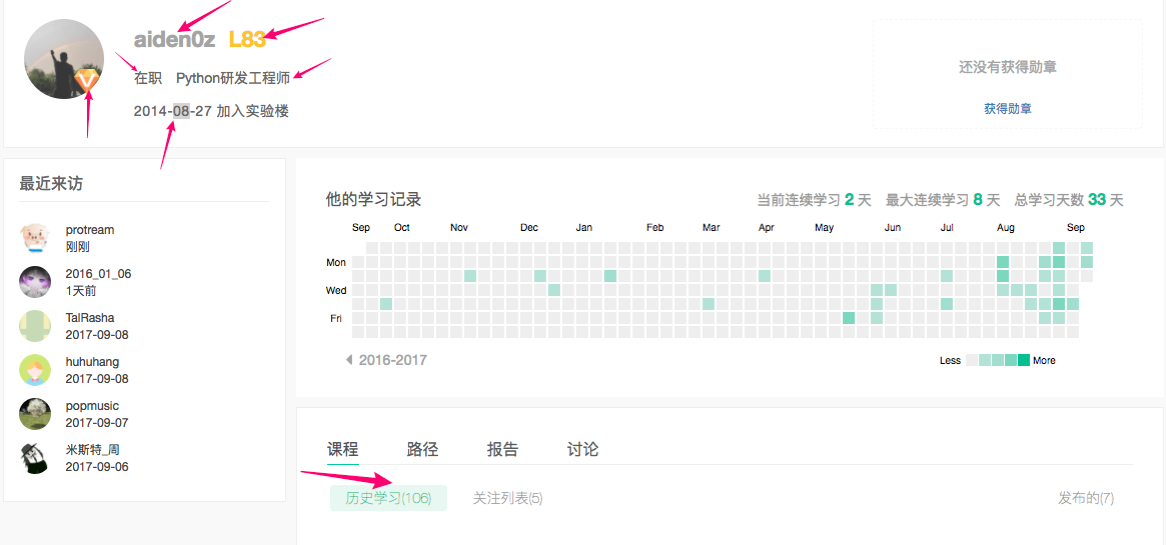
要爬取的内容和字段名称定义:
- 用户名 (name)
- 类型:普通用户/会员用户 (is_vip)
- 加入蓝桥的时间 (join_date)
- 楼层数 (level)
- 状态:在职/学生 (status)
- 学校/职位 (school_job)
- 学习记录 (study_record)
定义数据模型
意:本节实验的操作需要使用上一节 scrapy 创建的 shiyanlou 项目的代码,代码目录为 /home/shiyanlou/Code/shiyanlou
环境准备
xxxxxxxxxx51pip install scrapy2cd /home/shiyanlou/Code3scrapy startproject shiyanlou4cd /home/shiyanlou/Code/shiyanlou/shiyanlou/5touch ./models.py
决定好了要爬取的内容,就可以使用 SQLAlchemy 定义数据模型了,在上一节实验中创建的 /home/shiyanlou/Code/shiyanlou/shiyanlou/models.py 中的 Course 后面定义 User 模型:
使用桌面文件管理工具,找到/home/shiyanlou/Code/shiyanlou/shiyanlou/models.py ,右击,使用vscode打开文件,使用右侧剪切板工具,粘贴如下内容到models.py文件中:
xxxxxxxxxx361from sqlalchemy import create_engine2from sqlalchemy.ext.declarative import declarative_base3from sqlalchemy import Column, String, Integer4# User 表用到新类型要引入5from sqlalchemy import Date, Boolean6
7engine = create_engine('mysql://root@localhost:3306/shiyanlou?charset=utf8')8Base = declarative_base()9
10class Course(Base):11 __tablename__ = 'courses'12
13 id = Column(Integer, primary_key=True)14 name = Column(String(64), index=True)15 description = Column(String(1024))16 type = Column(String(64), index=True)17 students = Column(Integer)18 19
20class User(Base):21 __tablename__ = 'users'22
23 id = Column(Integer, primary_key=True)24 name = Column(String(64), index=True)25 # 用户类型有普通用户和会员用户两种,我们用布尔值字段来存储26 # 如果是会员用户,该字段的值为 True ,否则为 False27 # 这里需要设置字段的默认值为 False28 is_vip = Column(Boolean, default=False)29 status = Column(String(64), index=True)30 school_job = Column(String(64))31 level = Column(Integer, index=True)32 join_date = Column(Date)33 learn_courses_num = Column(Integer)34 35if __name__ == '__main__':36 Base.metadata.create_all(engine)使用终端工具,运行脚本在数据库中创建 users 表了:
创建数据库
以 root 身份进入 mysql,实验环境默认是没有密码的:
xxxxxxxxxx21sudo service mysql start2mysql -uroot创建 shiyanlou 库给本实验使用:
xxxxxxxxxx21CREATE DATABASE shiyanlou;2exit;
安装依赖包
xxxxxxxxxx61pip install scrapy2pip install sqlalchemy3pip install mysqlclient4sudo apt-get install -y libmysqlclient-dev5cd /home/shiyanlou/Code/shiyanlou/shiyanlou/6python3 ./models.pySQLAlchemy 默认不会重新创建已经存在的表,所以不用担心 create_all 会重新创建 course 表造成数据丢失;
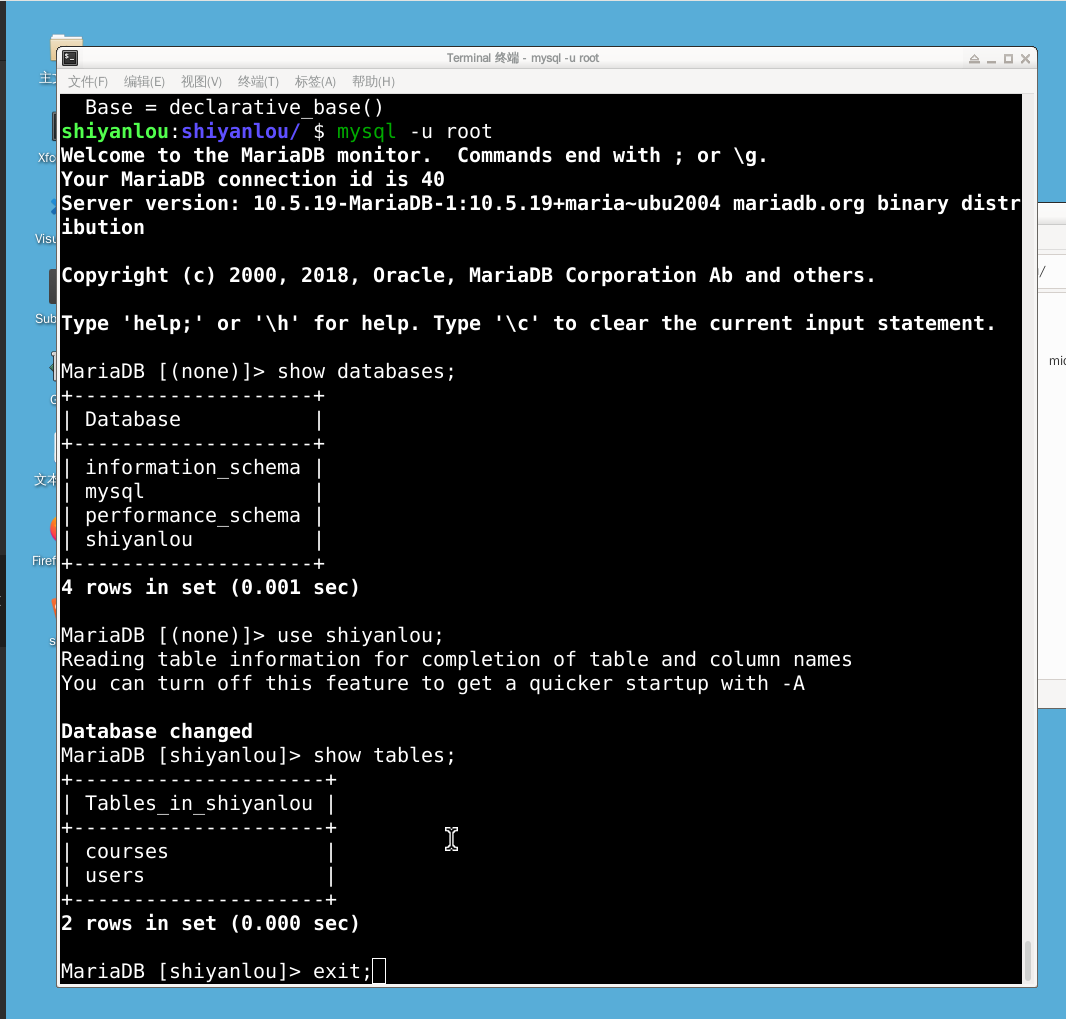
运行完成后验证表是否创建
xxxxxxxxxx51mysql -uroot2show databases;3use shiyanlou;4show tables;5exit;
结果如下,如果有courses和users表,说明创建表的脚本执行成功:
创建 Item
在 /home/shiyanlou/Code/shiyanlou/shiyanlou/items.py 中添加 UserItem,为每个要爬取的字段声明一个 Field:
使用桌面浏览器,使用vscode打开items.py进行修改
在文件末尾添加UserItem类,文件结果如下:
xxxxxxxxxx211import scrapy2
3
4class CourseItem(scrapy.Item):5 """6 定义 Item 非常简单,只需要继承 scrapy.Item 类,将每个要爬取的数据声明为 scrapy.Field()7 下面的代码是我们每个课程要爬取的 4 个数据8 """9 name = scrapy.Field()10 description = scrapy.Field()11 type = scrapy.Field()12 students = scrapy.Field()13 14class UserItem(scrapy.Item):15 name = scrapy.Field()16 is_vip = scrapy.Field()17 status = scrapy.Field()18 school_job = scrapy.Field()19 level = scrapy.Field()20 join_date = scrapy.Field()21 learn_courses_num = scrapy.Field()如图示:
创建爬虫
使用 genspider 命令创建 users 爬虫:
xxxxxxxxxx21cd /home/shiyanlou/Code/shiyanlou/shiyanlou/2scrapy genspider users lanqiao.cn如图示:
使用vscode打开/home/shiyanlou/Code/shiyanlou/shiyanlou/目录下的:users.py
Scrapy 为我们在 spiders 下面创建 users.py 爬虫,将它修改如下:
xxxxxxxxxx141import scrapy2
3class UsersSpider(scrapy.Spider):4 name = 'users'5
6 7 def start_urls(self):8 """9 蓝桥注册的用户数目前大约六十几万,为了爬虫的效率,10 取 id 在 524,800~525,000 之间的新用户,11 每间隔 10 取一个,最后大概爬取 20 个用户的数据12 """13 url_tmp = 'https://www.lanqiao.cn/users/{}/'14 return (url_tmp.format(i) for i in range(525000, 524800, -10))解析数据
解析数据主要是编写 parse 函数。在实际编写前,最好是用 scrapy shell 对某一个用户进行测试,将正确的提取代码复制到 parse 函数中。
下面的几个例子是 “需要提取的某用户数据在页面源码中的结构” 和对应的提取器(提取器有很多种写法,可以用自己的方式去写)
xxxxxxxxxx381# 以下为用户页面部分源码2
3<div class="user-meta" data-v-22a7bf90>4 <span data-v-22a7bf90> 幺幺哒 </span>5 <span data-v-22a7bf90> L2282 </span>6 <!---->7 <!---->8</div>9<div data-v-1b7bcd86 data-v-22a7bf90>10 <div class="user-status" data-v-1b7bcd86>11 <span data-v-1b7bcd86> 学生 </span>12 <span data-v-1b7bcd86> 格瑞魔法学校 </span>13 </div>14</div>15<span class="user-join-date" data-v-22a7bf90> 2016-11-10 加入蓝桥 </span>16# name17# 提取结果为字符串,strip 方法去掉前后的空白字符18# 空白字符包括空格和换行符19response.css('div.user-meta span::text').extract()[0].strip()20
21# level22# 注意提取结果的第一个字符是 L23response.css('div.user-meta span::text').extract()[1].strip()24
25# status26# 该字段为用户个人信息,如果用户未设置,提取不到数据27# 这种情况将其设为“无”28response.css('div.user-status span::text').extract_first(default='无').strip()29
30# school_job31# 该字段同上,这里需要使用 xpath 提取器32response.xpath('//div[@class="user-status"]/span[2]/text()').extract_first(default='无').strip()33
34# learn_courses_num35# 使用正则表达式来提取数字部分36# \D+ 匹配多个非数字字符,\d+ 匹配多个数字字符37# 大家可以尝试使用同样的方法修改 level 提取器的写法38response.css('span.tab-item::text').re_first('\D+(\d+)\D+')如下图所示,会员用户头像右下角有一个会员标志,它是一张图片。在 div 标签下,非会员用户只有一个 img 标签在 a 标签内部,会员用户有两个 img 标签,我们可以根据 img 的数量来判断用户类型:
xxxxxxxxxx21if len(response.css('div.user-avatar img').extract()) == 2:2 item['is_vip'] = True依次在 scrapy shell 中测试每个要爬取的数据,最后将代码整合进 users.py 中如下:
xxxxxxxxxx261import scrapy2from ..items import UserItem3
4
5class UsersSpider(scrapy.Spider):6 name = 'users'7 allowed_domains = ['lanqiao.cn']8
9 10 def start_urls(self):11 url_temp = 'https://www.lanqiao.cn/users/{}'12 return (url_temp.format(i) for i in range(525000, 524800, -10))13
14 def parse(self, response):15 item = UserItem(16 name = response.css('div.user-meta span::text').extract()[0].strip(),17 level = response.css('div.user-meta span::text').extract()[1].strip(),18 status = response.css('div.user-status span::text').extract_first(default='无').strip(),19 school_job = response.xpath('//div[@class="user-status"]/span[2]/text()').extract_first(default='无').strip(),20 join_date = response.css('span.user-join-date::text').extract_first().strip(),21 learn_courses_num = response.css('span.tab-item::text').re_first('\D+(\d+)\D+')22 )23 if len(response.css('div.user-avatar img').extract()) == 2:24 item['is_vip'] = True25
26 yield itempipeline
因为 pipeline 会作用在每个 item 上,当和课程爬虫共存时,需要根据 item 类型使用不同的处理函数。
最终代码文件 /home/shiyanlou/Code/shiyanlou/shiyanlou/pipelines.py:
xxxxxxxxxx381from datetime import datetime2from sqlalchemy.orm import sessionmaker3from shiyanlou.models import Course, User, engine4from shiyanlou.items import CourseItem, UserItem5
6
7class ShiyanlouPipeline(object):8
9 def process_item(self, item, spider):10 """ 对不同的 item 使用不同的处理函数11 """12 if isinstance(item, CourseItem):13 self._process_course_item(item)14 else:15 self._process_user_item(item)16 return item17
18 def _process_course_item(self, item):19 item['students'] = int(item['students'])20 self.session.add(Course(**item))21
22 def _process_user_item(self, item):23 # 抓取到的数据类似 'L100',需要去掉 'L' 然后转化为 int24 item['level'] = int(item['level'][1:])25 # 抓取到的数据类似 '2017-01-01 加入蓝桥',把其中的日期字符串转换为 date 对象26 item['join_date'] = datetime.strptime(item['join_date'].split()[0], '%Y-%m-%d')27 # 学习课程数目转化为 int28 item['learn_courses_num'] = int(item['learn_courses_num'])29 # 添加到 session30 self.session.add(User(**item))31
32 def open_spider(self, spider):33 Session = sessionmaker(bind=engine)34 self.session = Session()35
36 def close_spider(self, spider):37 self.session.commit()38 self.session.close()运行
使用 crawl 命令启动爬虫:
xxxxxxxxxx21cd /home/shiyanlou/Code/shiyanlou/shiyanlou/2scrapy crawl users总结
实验设计了一个新的实例,爬取蓝桥的用户页面,在这个页面中首先需要分析页面中的各种元素,从而设计爬虫中数据提取的方式。然后把需要的数据内容通过 Scrapy 项目中的代码获取得到并解析出来,存储到数据库中。
本节实验包含以下的知识点:
- Scrapy 项目框架
- 分析网页元素字段
- SQLAlchemy 定义数据模型
- 创建 Item
- 解析数据
【本地实验】Scrapy 爬取蓝桥用户数据
简介
本节实验的操作在笔记本上,数据库使用远程数据库,暂使用内网地址:10.0.10.158,端口:3306
环境准备
xxxxxxxxxx71pip install scrapy2d:3mkdir d:\\myname4cd d:\\myname5scrapy startproject shiyanlou6cd d:\\myname\shiyanlou\shiyanlou\7echo '' > models.py
使用pycharm打开目录d:\myname\shiyanlou\

修改D:\myname\shiyanlou\shiyanlou\models.py 文件,内容如下:
xxxxxxxxxx421from sqlalchemy import create_engine2from sqlalchemy.ext.declarative import declarative_base3from sqlalchemy import Column, String, Integer4# User 表用到新类型要引入5from sqlalchemy import Date, Boolean6
7engine = create_engine('mysql://test:test@home.hddly.cn:53306/test?charset=utf8')8Base = declarative_base()9
10
11class Course(Base):12 __tablename__ = 'courses'13
14 id = Column(Integer, primary_key=True)15 name = Column(String(64), index=True)16 description = Column(String(1024))17 type = Column(String(64), index=True)18 students = Column(Integer)19 collector = Column(String(64), index=True)20 coll_time = Column(Date)21
22class User(Base):23 __tablename__ = 'users'24
25 id = Column(Integer, primary_key=True)26 name = Column(String(640), index=True)27 # 用户类型有普通用户和会员用户两种,我们用布尔值字段来存储28 # 如果是会员用户,该字段的值为 True ,否则为 False29 # 这里需要设置字段的默认值为 False30 is_vip = Column(Boolean, default=False)31 status = Column(String(64), index=True)32 school_job = Column(String(64))33 level = Column(Integer, index=True)34 join_date = Column(Date)35 learn_courses_num = Column(Integer)36 stucode = Column(String(64), index=True)37 collector = Column(String(64), index=True)38 coll_time = Column(Date)39
40
41if __name__ == '__main__':42 Base.metadata.create_all(engine)安装依赖包
xxxxxxxxxx51pip install scrapy2pip install sqlalchemy3pip install mysqlclient4pip install fake-useragent5
修改 Items.py
items.py中添加UserItem,每个Item需要包含stucode,collector,coll_time信息,文件结果如下:
xxxxxxxxxx281import scrapy2
3
4class CourseItem(scrapy.Item):5 """6 定义 Item 非常简单,只需要继承 scrapy.Item 类,将每个要爬取的数据声明为 scrapy.Field()7 下面的代码是我们每个课程要爬取的 4 个数据8 """9 name = scrapy.Field()10 description = scrapy.Field()11 type = scrapy.Field()12 students = scrapy.Field()13 stucode = scrapy.Field()14 collector = scrapy.Field()15 coll_time = scrapy.Field()16
17
18class UserItem(scrapy.Item):19 name = scrapy.Field()20 is_vip = scrapy.Field()21 status = scrapy.Field()22 school_job = scrapy.Field()23 level = scrapy.Field()24 join_date = scrapy.Field()25 learn_courses_num = scrapy.Field()26 stucode = scrapy.Field()27 collector = scrapy.Field()28 coll_time = scrapy.Field()创建爬虫users.py
使用 genspider 命令创建 users 爬虫:
xxxxxxxxxx31d:2cd D:\myname\shiyanlou\shiyanlou\3scrapy genspider users lanqiao.cn修改 users.py 中如下:
xxxxxxxxxx491import scrapy2from fake_useragent import UserAgent3from scrapy import Request4
5from ..items import UserItem6
7
8class UsersSpider(scrapy.Spider):9 name = 'users'10 allowed_domains = ['lanqiao.cn']11
12 # @property13 # def start_urls(self):14 # url_temp = 'https://www.lanqiao.cn/users/{}'15 # return (url_temp.format(i) for i in range(525000, 523800, -1))16
17 def start_requests(self):18 ua = UserAgent()19 url_temp = 'https://www.lanqiao.cn/users/{}'20 for i in range(525000, 524800, -1):21 headers = {22 "User-Agent": ua.random,23 "Cookie" :'lqtoken=9992d82d0b28839fa52f2138f0c5ef83; _ga=GA1.2.148394195.1713187596; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%222432765%22%2C%22first_id%22%3A%2218edcdcb4911297-05af5f4e7352aa-26001a51-1395396-18edcdcb4922006%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMThlZGNkY2I0OTExMjk3LTA1YWY1ZjRlNzM1MmFhLTI2MDAxYTUxLTEzOTUzOTYtMThlZGNkY2I0OTIyMDA2IiwiJGlkZW50aXR5X2xvZ2luX2lkIjoiMjQzMjc2NSJ9%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%24identity_login_id%22%2C%22value%22%3A%222432765%22%7D%2C%22%24device_id%22%3A%2218edcdcb4911297-05af5f4e7352aa-26001a51-1395396-18edcdcb4922006%22%7D; _gid=GA1.2.56784145.1715653295; acw_tc=0b63bb3217156904608981869e599b3089309bec154217375bc6f9732da63b; Hm_lvt_56f68d0377761a87e16266ec3560ae56=1715306206,1715408219,1715652781,1715690462; platform=LANQIAO-FE; Hm_lvt_39c7d7a756ef8d66180dc198408d5bde=1715306207,1715408221,1715652782,1715690463; Hm_lpvt_39c7d7a756ef8d66180dc198408d5bde=1715690636; _ga_XY08NHY75L=GS1.2.1715690463.39.1.1715690641.0.0.0; tfstk=fU-iwEME8F76kbexsHjsYLgmPR3d15sfaIEAMiCq865Q65E93xjDtKvtCGpViEfeElLOk1d3YtXzQRSVbRTBwLr9XVsYmGsf0bh-20p9Cisqzt2XQ5_FnTmYgO7ZIgT6obh-2DphX96-wEhZlc_hh6WN3NWZKyWPIiPV0I5F8TW8_iS2gpkhHTEabtraYDWAIbz4J1QR-HkJ9OhJu_idtObGgoC3mttL2N5Pw6q46HXg__JNtorV1_WA_pvtsu9df3dleCnUjQv2FE7HmWllGHvebEJQsjWBuCIF6guaKGK6QU724ja2ZGAczh733uJ6Q6shL3kYP6Kh6I-G8YElkM-RzG8KRfQAjTA2fC200QJpeh_BmbVFGFB5YtxjUrfcug738zPipo6EHHzblNWCK_MaStc_TLmeNvD3zGbNdOyqKv4blNWCK_HnKz8G796a3; Hm_lpvt_56f68d0377761a87e16266ec3560ae56=1715692043'24 }25 url =url_temp.format(i)26 yield Request(url=url, headers=headers)27
28 def parse(self, response):29 item = UserItem(30 name = response.css('div.user-basic-info div span::text').extract()[0].strip(),31 # #__layout > div > div.body.no-padding > div.page-box > div > div.user-info-wrap.mb-20px > div.left > div.user-basic-info > div > div > span.name32 # #__layout > div > div.body.no-padding > div.page-box > div > div.user-info-wrap.mb-20px > div.left > div.user-basic-info > div > div > span.name33 level = response.css('div.user-basic-info div span::text').extract()[1].strip(),34 # #__layout > div > div.body.no-padding > div.page-box > div > div.user-info-wrap.mb-20px > div.left > div.user-basic-info > div > div > span.level35 status ='0',36
37 # school_job = response.xpath('//div[@class="user-status"]/span[2]/text()').extract_first(default='无').strip(),38 school_job = '',39 # join_date = response.css('span.user-join-date::text').extract_first().strip(),40 join_date = '1900-01-01',41 learn_courses_num = response.css('div.statistic-item.trial-number div.data span.value::text').extract_first().strip()42 # #__layout > div > div.body.no-padding > div.page-box > div > div.bottom-content > div.left >43 # div.card-panel.mb-20px > div > div.statistic-wrap > div.statistic-item.trial-number > div.data > span44 )45 if len(response.css('div.auth-content a div img').extract()) == 2:46 # #__layout > div > div.universal-header > div > div > div > div > div.auth-content > a > div > img47 item['is_vip'] = True48
49 yield item修改pipelines.py
因为 pipeline 会作用在每个 item 上,当和课程爬虫共存时,需要根据 item 类型使用不同的处理函数。
最终代码文件 pipelines.py:
需要修改open_spider方法中的stucode和collector值,请换成本人学号和姓名
xxxxxxxxxx491from datetime import datetime2
3from sqlalchemy.orm import sessionmaker4
5from .items import CourseItem6from .models import Course, User, engine7
8
9class ShiyanlouPipeline(object):10
11 def process_item(self, item, spider):12 """ 对不同的 item 使用不同的处理函数13 """14 item['stucode'] =self.stucode15 item['collector'] = self.collector16 item['coll_time'] = datetime.now()17 if isinstance(item, CourseItem):18 self._process_course_item(item)19 else:20 self._process_user_item(item)21 return item22
23 def _process_course_item(self, item):24 item['students'] = int(item['students'])25 self.session.add(Course(**item))26
27 def _process_user_item(self, item):28 # 抓取到的数据类似 'L100',需要去掉 'L' 然后转化为 int29 # if not str(item['name']).startswith('L'):30 # item['name']= str(str(item['name']).encode('utf-8'))31
32 item['level'] = int(item['level'][1:])33 # 抓取到的数据类似 '2017-01-01 加入蓝桥',把其中的日期字符串转换为 date 对象34 # item['join_date'] = datetime.strptime(item['join_date'].split()[0], '%Y-%m-%d')35 # 学习课程数目转化为 int36 item['learn_courses_num'] = int(item['learn_courses_num'])37 # 添加到 session38 self.session.add(User(**item))39 self.session.commit()40
41 def open_spider(self, spider):42 self.stucode = 'yuxm' # 请改为自已的学号,如:2227340111143 self.collector = '俞老师' # 请改为自已的名字44 Session = sessionmaker(bind=engine)45 self.session = Session()46
47 def close_spider(self, spider):48 self.session.commit()49 self.session.close()修改settings.py
修改settings文件开启ITEM_PIPELINES,在文件末尾添加如下:
xxxxxxxxxx71ITEM_PIPELINES = {2"shiyanlou.pipelines.ShiyanlouPipeline": 300,3}4DOWNLOAD_DELAY = 2 # 基础延迟时间6RANDOMIZE_DOWNLOAD_DELAY = True # 启用随机延迟7
运行爬虫
使用 crawl 命令启动爬虫:
xxxxxxxxxx31d:2cd D:\myname\shiyanlou\shiyanlou\3scrapy crawl users在IDE上运行
修改D:\myname\shiyanlou\shiyanlou__init__.py,内容如下,然后可右击该文件运行或调试
xxxxxxxxxx51from scrapy import cmdline2if __name__ == '__main__':4cmdline.execute("scrapy crawl users".split())5
随堂练习
练习内容:
在本地完成Scrapy 爬取蓝桥用户数据抓取 ,步骤包括环境准备、创建scrapy项目、修改items.py、创建爬虫users.py、创建爬虫users.py、修改settings.py、运行爬虫等,完成以上内容并截图
截图要求:
- 截图在云课环境上的运行截图,只需要scrapy crawl users运行截图
- 截图pycharm的源码,包括users.py,items.py,pipelines.py,settings.py新增的内容
- 截图在本机环境上运行scrapy crawl users的截图,截图中包含有已采集的数据和本人姓名
- 截图已采集数据量的截图,进入学生登陆-》统计积分-》采集统计,在mysql统计中选择会员信息统计
5.4 Scrapy 高级应用
【练一练】Scrapy 高级应用
实验简介
本节内容主要介绍使用 Scrapy 进阶的知识和技巧,包括页面追随、图片下载、组成 item 的数据在多个页面和模拟登录。
知识点
- 页面追随
- 图片下载
- Item 包含多个页面数据
- 模拟登录
页面跟随
在前面实现课程爬虫和用户爬虫中,因为蓝桥的课程和用户 URL 都是通过 id 来构造的,所以可以轻松构造一批顺序的 URLS 给爬虫。但是在很多网站中,URL 并不是轻松可以构造的,更常用的方法是从一个或者多个链接(start_urls)爬取页面后,再从页面中解析需要的链接继续爬取,不断循环。
下面是一个简单的例子,在蓝桥课程编号为 63 的课程主页,从页面底部相关课程推荐来获取下一批要爬取的课程的 URL ,我们的任务是爬取该课程和所有推荐课程的名字和作者。
结合前面所学的知识,你可能会写出类似这样的代码:
xxxxxxxxxx181import scrapy2
3
4class CoursesFollowSpider(scrapy.Spider):5 name = 'courses_follow'6 start_urls = ['https://lanqiao.cn/courses/63']7
8 def parse(self, response):9 yield {10 'name': response.css('h1.course-title::text').extract_first().strip(),11 'author': response.css('p.teacher-info span::text').extract_first()12 }13 # 从返回的 response 中提取 “推荐课程” 的链接14 # 依次构造请求,再将本函数指定为回调函数,类似递归15 for url in response.css('div.course-item-box a::attr(href)').extract():16 # 解析出的 url 是相对 url,可以手动将它构造为全 url17 # 或者使用 response.urljoin() 方法18 yield scrapy.Request(url=response.urljoin(url), callback=self.parse)完成页面跟随的核心就是最后 for 循环的代码。使用 response.follow 方法可以对 for 循环代码做进一步简化:
xxxxxxxxxx161import scrapy2
3
4class CoursesFollowSpider(scrapy.Spider):5 name = 'courses_follow'6 start_urls = ['https://www.lanqiao.cn/courses/63']7
8 def parse(self, response):9 yield {10 'name': response.css('h1.course-title::text').extract_first().strip(),11 'author': response.css('p.teacher-info span::text').extract_first()12 }13 # 不需要 extract 了14 for url in response.css('div.course-item-box a::attr(href)'):15 # 不需要构造全 url 了16 yield response.follow(url, callback=self.parse)图片下载
scrapy 内部内置了下载图片的 pipeline。下面以下载蓝桥课程首页每个课程的封面图片为例展示怎么使用它。注意项目的路径需要放置在 /home/shiyanlou/Code/ 下,命名为 shiyanlou。
可以新创建一个项目,也可以继续使用上一节实验的 scrapy 项目代码。
首先需要在 /home/shiyanlou/Code/shiyanlou/shiyanlou/items.py 中定义一个 item ,它包含两个必要的字段:
xxxxxxxxxx51class CourseImageItem(scrapy.Item):2 # 要下载的图片 url 列表3 image_urls = scrapy.Field()4 # 下载的图片会先放在这里5 images = scrapy.Field()运行 scrapy genspider courses_image lanqiao.cn/courses 生成一个爬虫,爬虫的核心工作就是解析所有图片的链接到 CourseImageItem 的 image_urls 中。 将以下代码写入 /home/shiyanlou/Code/shiyanlou/shiyanlou/spiders/courses_image.py 文件中:
xxxxxxxxxx141import scrapy2
3from shiyanlou.items import CourseImageItem4
5
6class CoursesImageSpider(scrapy.Spider):7 name = 'courses_image'8 start_urls = ['https://www.lanqiao.cn/courses/']9
10 def parse(self, response):11 item = CourseImageItem()12 #解析图片链接到 item13 item['image_urls'] = response.xpath('//img[@class="cover-image"]/@src').extract()14 yield item代码完成后需要在 settings.py 中启动 scrapy 内置的图片下载 pipeline,因为 ITEM_PIPELINES 里的 pipelines 会按顺序作用在每个 item 上,而我们不需要 ShiyanlouPipeline 作用在图片 item 上,所以要把它注释掉:
xxxxxxxxxx41ITEM_PIPELINES = {2 'scrapy.pipelines.images.ImagesPipeline': 100,3 # 'shiyanlou.pipelines.ShiyanlouPipeline': 3004}还需要配置图片存储的目录:
xxxxxxxxxx11IMAGES_STORE = 'images'运行程序:
xxxxxxxxxx51# 安装需要的 PIL 包,pillow 是前者的一个比较好的实现版本2$ pip3 install pillow3
4# 执行图片下载爬虫5$ scrapy crawl courses_imagescrapy 会将图片下载到 images/full 下面,保存的文件名是对原文件进行的 hash。为什么会有一个 full 目录呢?full 目录用于存储原尺寸的图片,因为 scrapy 可以配置改变下载图片的尺寸,比如在 settings 中给你添加下面的配置生成小图片:
xxxxxxxxxx31IMAGES_THUMBS = {2 'small': (50, 50)3}组成 item 的数据在多个页面
在前面几节实现的爬虫中,组成 item 的数据全部都是在一个页面中获取的。但是在实际的爬虫项目中,经常需要从不同的页面抓取数据组成一个 item。下面通过一个例子展示如何处理这种情况。
有一个需求,爬取蓝桥课程首页所有课程的名称、封面图片链接和课程作者。课程名称和封面图片链接在课程主页 https://www.shiyanlou.cn/courses/ 就能爬到,课程作者只有点击课程,进入课程详情页面才能看到,怎么办呢?
scrapy 的解决方案是多级 request 与 parse 。简单地说就是先请求课程首页,在回调函数 parse 中解析出课程名称和课程图片链接,然后在 parse 函数中再构造一个请求到课程详情页面,在处理课程详情页的回调函数中解析出课程作者。
首先在 items.py 中创建相应的 Item 类:
xxxxxxxxxx41class MultipageCourseItem(scrapy.Item):2 name = scrapy.Field()3 image = scrapy.Field()4 author = scrapy.Field()终端执行如下命令生成一个爬虫脚本:
xxxxxxxxxx11$ scrapy genspider multipage www.lanqiao.cn操作截图:
如上图所示,打开 multipage.py 文件并修改代码如下:
xxxxxxxxxx331import scrapy2
3from shiyanlou.items import MultipageCourseItem4
5
6class MultipageSpider(scrapy.Spider):7 name = 'multipage'8 start_urls = ['https://www.lanqiao.cn/courses/']9
10 def parse(self, response):11 for course in response.css('div.col-md-3'):12 item = MultipageCourseItem(13 # 解析课程名称14 name=course.css('h6.course-name::text').extract_first().strip(),15 # 解析课程图片16 image=course.css('img.cover-image::attr(src)').extract_first()17 )18 # 构造课程详情页面的链接,爬取到的链接是相对链接,调用 urljoin 方法构造全链接19 course_url = course.css('a::attr(href)').extract_first()20 full_course_url = response.urljoin(course_url)21 # 构造到课程详情页的请求,指定回调函数22 request = scrapy.Request(full_course_url, self.parse_author)23 # 将未完成的 item 通过 meta 传入 parse_author24 request.meta['item'] = item25 yield request26
27 def parse_author(self, response):28 # 获取未完成的 item29 item = response.meta['item']30 # 解析课程作者31 item['author'] = response.css('p.teacher-info span::text').extract_first()32 # item 构造完成,生成33 yield item关闭所有的 pipeline,运行爬虫,保存结果到文件中:
xxxxxxxxxx11$ scrapy crawl multipage -o /home/shiyanlou/Code/shiyanlou/shiyanlou/data.json这部分的知识点不容易理解,可以参考下先前同学的一个提问来理解 https://www.lanqiao.cn/questions/50921/
模拟登录
有些网页需要登录后才能访问,例如任何网站的用户个人主页。有些网页中的部分内容需要登录后才能看到,例如 GitHub 中的私有仓库。
如果想要爬取登录后才能看到的内容就需要 Scrapy 模拟出登录的状态再去抓取页面,解析数据。这个实验就是要模拟登录自己的主页。
通常网站都会有一个 login 页面,GitHub 的 login 页面网址是:https://github.com/login。在浏览器的地址栏输入这个地址敲回车:
鼠标右键选择“检查”,打开开发者工具栏,选择 Network :
在页面的登录表单中输入错误的用户名和密码,点击“登录”按钮。如下图所示,右侧出现 session 请求,点击此文件,出现请求和响应信息:
点击登录按钮后,会有一个 POST 请求发送给服务器。在 Form Data 中可以看到本次提交的内容。
其中红色框中的 token 字段是关键信息,为了防止跨域伪造攻击,网站通常会在表单中添加一个隐藏域来放置这个 token 字段。当浏览器发送携带表单的 POST 请求时,服务器收到请求后会比对表单中的 token 字段与 Cookies 中的信息以判断请求来源的可靠性。
所以我们在发送 POST 登录请求时,就要携带这个 token 字段。
如何获取这个字段呢?很简单,在登录页的源码上就会有。在开发者工具栏中打开页面源码,搜索 "token" 关键字即可:
也就是 form 标签下的第一个 input 标签的 value 属性值。
要获取 token 值,就要发送一次请求。将如下代码写入 /home/shiyanlou/github_login.py 文件中:
xxxxxxxxxx121import scrapy2
3
4class GithubSpider(scrapy.Spider):5 name = 'github_login'6 start_urls = ['https://github.com/login']7
8 def parse(self, response):9 token = response.xpath('//form/input[1]/@value').extract_first()10 print('==================================')11 print('TOKEN:', token)12 print('==================================')以上代码会向 GitHub 发送一次登录请求,我们可以通过响应对象获取隐藏在表单中的 token 字段。
针对本次模拟登录的学习,我们要安装 Scrapy 2.1 版本:
xxxxxxxxxx11$ sudo pip install scrapy==2.1在执行 scrapy runspider 命令时,可以使用 -L 选项设置打印信息的级别。为了避免多余的普通信息出现在屏幕上,我们设置打印级别为 ERROR ,也就是只打印错误信息。
现在在终端执行如下命令:
xxxxxxxxxx11$ scrapy runspider -L ERROR github_login.py此命令执行顺利的话,会打印 token 字段到屏幕上。操作截图如下:
有了 token 字段,就可以构造 POST 登录请求了。这次请求与前一次的地址相同,请求方法不同。
这种情况,我们可以使用 scrapy.FormRequest.from_response 方法构造 POST 请求。
修改 github_login.py 文件如下:
xxxxxxxxxx291import scrapy2
3
4class GithubSpider(scrapy.Spider):5 name = 'github_login'6 start_urls = ['https://github.com/login']7
8 def parse(self, response):9 # 获取 token 字段10 token = response.xpath('//form/input[1]/@value').extract_first()11 print('==================================')12 print('TOKEN:', token)13 print('==================================')14 # 构造 POST 登录请求15 return scrapy.FormRequest.from_response(16 # 第一个参数为上次请求的响应对象,这是固定写法17 response,18 # 将 token 字段和用户信息作为表单数据19 formdata = {20 'authenticity_token': token,21 'login': '用户名',22 'password': '密码'23 },24 callback = self.after_parse,25 )26
27 def after_parse(self, response):28 print('STATUS:', response.status)29 print('==================================')再次执行程序:
这样就登录成功了。现在可以爬取你自己的私有仓库和个人主页。
*注:由于原网页随时会发生变化,所以爬虫代码往往是即时代码,有效期由每个网站决定,主要看思路和框架
总结
本节内容主要通过蓝桥用户爬虫的代码实例介绍如何使用 Scrapy 进阶的知识和技巧,包括页面追随,图片下载, 组成 item 的数据在多个页面,模拟登录等。
本节实验中涉及到的知识点:
- 页面追随
- 图片下载
- Item 包含多个页面数据
- 模拟登录
完成本周的学习之后,我们再次根据脑图的知识点进行回顾,让动手实践过程中学习到的知识点建立更加清晰的体系。
请点击以下链接回顾本周的 Scrapy 爬虫框架的学习:
请注意实验只会包含常用的知识点,对于未涉及到的知识点,如果在脑图中看到可以查看 Scrapy 官方文档获得详细说明,也非常欢迎在讨论组里与同学和助教进行讨论,技术交流也是学习成长的必经之路