第4章Selenium爬虫
(源自:https://biglab.site)
(版本:Ver1.0-20240422)
第4章Selenium爬虫初识 Selenium实验介绍知识点安装需要的库实验环境selenium 介绍安装 Firefox安装 Seleniumgeckodriver 驱动本地安装geckodriver 驱动在云课上编码实验浏览器操作在pycharm上实验实验总结参考链接网页元素定位实验介绍知识点定位元素点击定位到的元素清空文本框、向文本框输入内容获取元素属性实验总结常用功能实验介绍知识点下拉页面页面弹窗 alert 的定位切换窗口定位 iframe实验总结
初识 Selenium
实验介绍
本节课程介绍 Selenium 的功能作用及安装、环境配置,并介绍 Selenium 常用的语法。
知识点
- Selenium 介绍
- 安装 Selenium
- 安装 geckodriver 浏览器驱动
- Selenium 的元素定位
- 点击元素
- 清空文本输入框、向文本输入框输入文本
- 获取元素属性
- 下拉页面
- 页面弹窗的定位以及弹窗文本的获取
- 窗口跳转
- iframe 定位
安装需要的库
xxxxxxxxxx21pip3 install --upgrade pip2pip3 install selenium实验环境
- Firefox 浏览器
- python 3
- geckodriver 0.30.0
- selenium 3
selenium 介绍
当我们进入selenium 官网时可以看到,首页写的是 Selenium automates browsers. That's it!,翻译过来就是“Selenium 是自动化浏览器”。也就是说我们把平时在网页上做的功能测试用 Selenium 代码实现,这样在回归测试的时候就可以达到省时省力的目的。
Selenium 在工作中的应用常见于功能基本稳定、没有频繁大变动的网页。所以我们一般是在业务功能上线以后,为确保页面稳定,用 Selenium 实现自动化回归测试,结合 git、Jenkins 一起,每当有新功能上线时都会执行写好的 Selenium 代码以验证新上线的业务对原有页面功能没有造成影响。如有报错,则发送相应的通知,这样就可以确保对线上功能出现的未预期 bug 进行及时的修复。
安装 Firefox
进入firefox官网下载最新版本:Firefox官网下载
安装 Selenium
在终端安装最新版本的 Selenium。
xxxxxxxxxx11pip install selenium --upgradegeckodriver 驱动
既然名为网页浏览器自动化自然要安装浏览器,一般来说,Chrome、Firefox等浏览器都可以,这里我们使用当前系统自带的Firefox作为实验浏览器。
通常,我们需要去下载浏览器对应的驱动,比如 Firefox 浏览器要下载 geckodriver 驱动,然后放到 /usr/local/bin文件夹中。当前环境中已经内置了驱动,了解步骤即可。
本地安装geckodriver 驱动
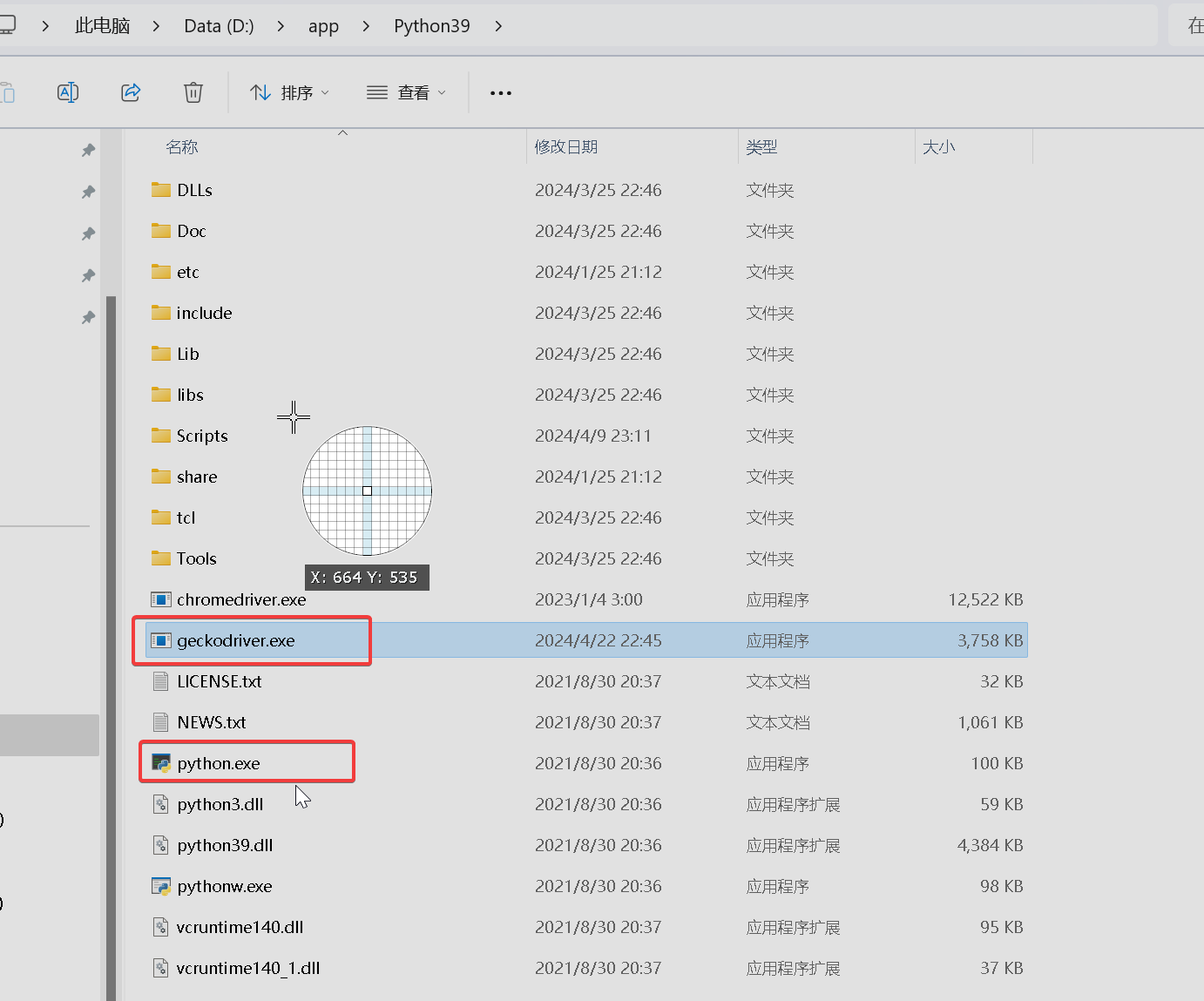
进官网下载驱动:geckodriver 下载链接 下载最新版本,windows下载win32版本

将下载来的geckodriver-v0.34.0-win32.zip 解压出来文件:geckodriver.exe ,并将该文件复制到python.exe相同的目录下
在云课上编码实验
打开终端,将目录切换至桌面:
xxxxxxxxxx21cd /home/shiyanlou/Desktop2touch ./demo.py下面我们来验证是否正常安装,在桌面上双击demo.py打开文件并写入代码:
xxxxxxxxxx61#! /usr/bin/python32
3from selenium import webdriver4
5driver = webdriver.Firefox()6driver.get("https://www.lanqiao.cn")在终端上输入python3 demo.py如果浏览器打开并进入我们的网站,则环境配置就成功了。
浏览器操作
在终端使用命令vim demo2.py创建文件并写入代码:
xxxxxxxxxx281#! /usr/bin/python32
3from selenium import webdriver4from time import sleep5
6
7driver = webdriver.Firefox()8
9# 浏览器进入百度网站10driver.get("https://www.baidu.com")11
12# 设置浏览器宽800,高40013driver.set_window_size(800, 400)14
15# 等待3秒16sleep(3)17
18# 刷新页面19driver.refresh()20
21# 等待3秒22sleep(3)23
24# 最大化窗口25driver.maximize_window()26
27# 退出浏览器28driver.quit()以上代码会在浏览器中执行:
- 打开浏览器
- 进入百度网站
- 设置窗口大小为宽 800,高 400
- 等待 3 秒
- 刷新页面
- 最大化窗口
- 退出浏览器
说明:由于环境限制,当前浏览器不能实现后退操作,所以如果大家在本地搭建环境,可以增加:
- 倒退页面
- 前进页面
代码示例如下:
xxxxxxxxxx351#! /usr/bin/python32
3from selenium import webdriver4from time import sleep5
6
7driver = webdriver.Firefox()8
9# 浏览器进入百度网站10driver.get("https://www.baidu.com")11
12# 设置浏览器宽800,高40013driver.set_window_size(800, 400)14
15# 等待3秒16sleep(3)17
18# 最大化窗口19driver.maximize_window()20# 进入另一个网站21driver.get("https://www.lanqiao.cn/")22sleep(3)23
24# 后退到上一个页面--百度网站25driver.back()26
27sleep(3)28
29# 前进到下一个页面--实验楼网站30driver.forward()31
32sleep(3)33
34# 退出浏览器35driver.quit()在pycharm上实验
在项目根目录下创建目录ch09,在ch09目录下创建文件:selenium_lanqiao_myname.py
脚本源码:
xxxxxxxxxx361#! /usr/bin/python32from selenium import webdriver4from time import sleep5driver = webdriver.Firefox()8# 浏览器进入百度网站10driver.get("https://www.baidu.com")11# 设置浏览器宽800,高40013driver.set_window_size(800, 400)14# 等待3秒16sleep(3)17# 最大化窗口19driver.maximize_window()20# 进入另一个网站21driver.get("https://www.lanqiao.cn/")22sleep(3)23# 后退到上一个页面--百度网站25driver.back()26sleep(3)28# 前进到下一个页面--实验楼网站30driver.forward()31sleep(3)33# 退出浏览器35driver.quit()36
运行结果如:

实验总结
本次实验我们介绍了 Selenium 的用途、环境配置以及基本操作,为后续完成 Selenium 代码做好了准备工作。
参考链接
网页元素定位
实验介绍
本节实验,我们将主要介绍基于 xpath 和 css 选择器,使用 selenium 进行网页元素的定位。
知识点
- 定位元素
- xpath 语法
- css 选择器
定位元素
webdriver 提供了一系列的元素定位方法,常用的有以下几种:
- id
- name
- class name
- tag name
- link text
- partial link text
- xpath
- css selector
分别对应 python webdriver 中的方法为:
- find_element_by_id()
- find_element_by_name()
- find_element_by_class_name()
- find_element_by_tag_name()
- find_element_by_link_text()
- find_element_by_partial_link_text()
- find_element_by_xpath()
- find_element_by_css_selector()
点击定位到的元素
click()
使用方法:一般为先进行元素的定位,如果该元素可以点击如:超链接、文本框、带有超链接的图片等,则该元素可以进行点击操作:
find_element_by_xxx().click()。
清空文本框、向文本框输入内容
- 清空:
clear() - 输入:
.send_keys("输入的内容")
使用方法:无论是清空还是输入操作,都是先进行元素即文本框的定位,然后调用对应的方法,即:清空
find_element_by_xx().clear(),输入find_element_by_xx().send_keys("输入的内容")
获取元素属性
- 文本信息:
.text
使用方法:定位到对应元素以后,直接调用方法:
find_element_by_xx().text,注意:text 后面不要加括号
- 元素尺寸:
.size
使用方法:同上
- 其他属性:
.get_attribute("想获取的属性名")
使用方法:定位到对应元素以后,调用
.get_attribute("属性名")方法,传值为想获取的属性名。注:查看元素的各个属性可通过 Chrome 自带的开发者工具,快捷键为F12,通过元素查看器定位到想查看的元素,然后在开发者工具中查看具体的属性名,如class、type、id等。
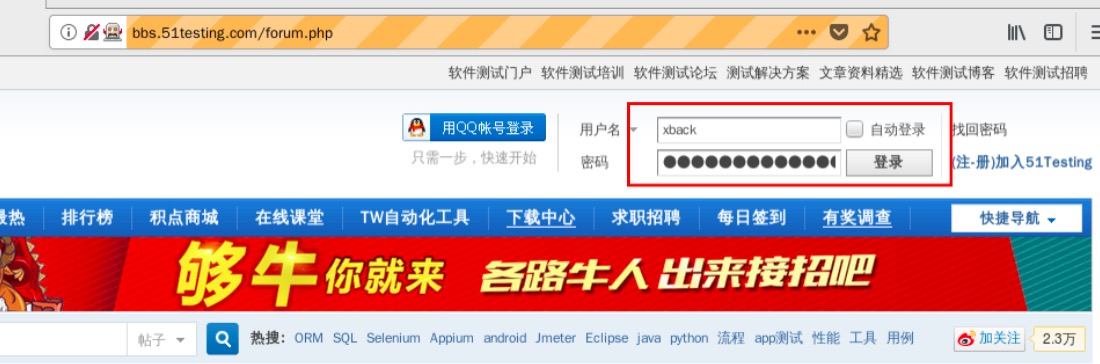
这里我们使用51Testing 软件测试论坛作为演示网站,如果大家没有账号需要先去注册一个,下面的代码将会使用到账号信息,在终端使用命令vim demo3.py创建文件并写入代码:
xxxxxxxxxx321#! /usr/bin/python32
3from selenium import webdriver4from time import sleep5
6
7driver = webdriver.Firefox()8
9# 进入51testing网站10driver.get("http://bbs.51testing.com/forum.php")11sleep(3)12
13# 用id定位账号输入框并输入账号14driver.find_element_by_id("ls_username").send_keys("您的用户名")15
16# 用id定位密码输入框并输入密码17driver.find_element_by_id("ls_password").send_keys("密码")18
19# 定位“登录”按钮并获取登录按钮的文本20txt = driver.find_element_by_xpath('//*[@id="lsform"]/div/div[1]/table/tbody/tr[2]/td[3]/button').text21
22# 打印获取的文本23print(txt)24
25# 定位“登录”按钮并获取登录按钮的type属性值26type = driver.find_element_by_xpath('//*[@id="lsform"]/div/div[1]/table/tbody/tr[2]/td[3]/button').get_attribute("type")27
28# 打印type属性值29print(type)30
31# 定位“登录”按钮并进行点击操作32driver.find_element_by_xpath('//*[@id="lsform"]/div/div[1]/table/tbody/tr[2]/td[3]/button').click()在终端执行python3 demo3.py运行,结果显示如下:
页面显示:
执行以上代码后会在 xfce 中输出如下信息:

实验总结
本节实验,我们结合 xpath 和 css 选择器使用 selenium 进行网页元素选择。
常用功能
实验介绍
本节实验,我们将介绍更多的 selenium 的操作,包括下拉页面、页面弹窗、切换窗口、定位 iframe。
知识点
- 下拉页面
- 页面弹窗
- 切换窗口
- 定位 iframe
下拉页面
说明:下拉页面需要用 js 命令
- 下拉指定高度
xxxxxxxxxx21js = 'document.documentElement.scrollTop=具体的下拉高度值;'2driver.execute_script(js)解释:
js = 'document.documentElement.scrollTop=具体的下拉高度值;'为 js 语句,意为下拉页面滚动条;driver.execute_script(js)为 python 代码,意为执行上面的 js 语句。
- 用目标元素做参考下拉页面
xxxxxxxxxx51target_element = driver.find_element_by_xx()2
3js = 'arguments[0].scrollIntoView();'4
5driver.execute_script(js,target_element)解释:
target_element = driver.find_element_by_xx()先对目标元素进行定位;js = 'arguments[0].scrollIntoView();'js 下拉命令;driver.execute_script(js, target_element)python 代码,执行脚本,传两个参数,第一个是 js 命令,第二个是目标元素。
在终端使用命令vim demo4.py创建文件并写入代码:
xxxxxxxxxx121#! /usr/bin/python32
3from selenium import webdriver4from time import sleep5
6driver = webdriver.Firefox()7driver.get("http://bbs.51testing.com/forum.php")8sleep(3)9
10# 页面下拉指定高度11js = 'document.documentElement.scrollTop=800;'12driver.execute_script(js)在终端执行python3 demo4.py运行,页面在等待 3 秒后会出现下拉行为
页面弹窗 alert 的定位
如果页面有alert形式的提醒框,则用以下语句
- driver.switch_to.alert
xxxxxxxxxx131alert = driver.switch_to.alert2
3# 查看alert中的文字4
5print(alert.text)6
7# 点击确定8
9alert.accept()10
11# 点击取消(如果有)12
13alert.dismiss()切换窗口
- .switch_to.window()
说明:很多时候我们点击按钮以后会新开页面,这时候要根据页面的
句柄来切换窗口,获取所有页面句柄方法为.window_handles,而获取当前页面的句柄语法则为.current_window_handle,现在我们假设页面开了两个窗口,那么如何在两个窗口之间进行切换呢?很简单,就是用一个for循环即可,如果循环到的句柄与当前句柄不一致,那么就切换句柄:
xxxxxxxxxx101# 获取窗口所有句柄2all_handles = driver.window_handles3# 获取当前窗口句柄4curr_window = driver.current_window_handle5# 遍历所有句柄6for k in all_handles:7 # 如果不是当前窗口句柄8 if k != curr_window:9 # 窗口句柄切换10 driver.switch_to.window(k)定位 iframe
- .switch_to.frame():切换到 iframe
- .switch_to.default_content(): 切换出 iframe
说明:iframe 经常在账号、密码输入框、发帖内容编辑框处出现,一般我们需要先通过开发人员工具确定该输入框是否是 iframe,如果是,则需要先定位 iframe。对 iframe 定位,一般需要先通过 xpath 定位到 iframe 的位置,然后通过
.switch_to.frame()方法切换到 iframe 中,iframe 就像一个盒子,我们进入了盒子内部,进行预期的操作,然后需要跳出盒子才能继续对页面元素进行操作,所以执行完 iframe 内的操作后需要跳出 iframe 可以通过.switch_to.default_content()方法。
xxxxxxxxxx111iframe = driver.find_element_by_xpath()2
3# 切换到iframe4
5driver.switch_to.frame(iframe)6
7"""页面操作代码"""8
9# 跳出iframe10
11driver.switch_to.default_content()实验总结
本节实验,我们介绍了更多的 selenium 的操作,包括下拉页面、页面弹窗、切换窗口、定位 iframe。当然, selenium 的操作不止我们讲到的这些,更多的内容可以多看官方文档。