第3章数据解析BS4
(源自:https://biglab.site)
(版本:Ver1.0-20240310)
第3章数据解析BS43.1 BeautifulSoup库【练一练】BeautifulSoup 库实验介绍知识点安装模块初识 BeautifulSoup基本的标签搜素标签文本的获取标签属性值的获取标签搜索的进阶实验总结提示【试一试】爬取并解析网站介绍目标要求3.2 初识 Xpath【练一练】初识 Xpath实验介绍知识点xpath 介绍XPath 语法利用浏览器定位 xpath手写 XPath例子一例子二实验总结3.3 Xpath 获取节点对象【练一练】Xpath 获取节点对象实验介绍知识点安装 lxml 模块目标网站etree 模块的 HTML 方法获取所有节点获取子节点属性匹配节点通过子节点获取父节点方法一方法二实验总结3.4 Xpath 获取文本数据【练一练】Xpath 获取文本数据实验介绍知识点目标网站通过 /text() 获取文本内容通过 //text() 获取所有文本内容节点对象的 text 属性实验总结3.5 Xpath 获取属性值【练一练】Xpath 获取属性值实验介绍知识点目标网站Xpath 获取 href 属性Xpath 获取 class 属性通过对象方法获取属性值实验总结3.6 Xpath 更多节点选择【练一练】Xpath 更多节点选择实验介绍知识点目标网站按序选择节点轴选择实验总结
3.1 BeautifulSoup库
【练一练】BeautifulSoup 库
实验介绍
前面我们学习了使用 requests 模块进行网页的抓取和保存,但网页数据通常是超文本格式的,内容都包含很多标签,接下来就需要对抓取到的网页进行解析,从中提取出需要的内容。
本节我们将介绍 Python 中一个常用模块 BeautifulSoup(靓汤),功能包括解析 HTML、XML 文档、修复含有未闭合标签等错误的文档。名字的由来是因为在网页开发中常把语法错误和用法混乱的标签称为 tag soup(大杂烩),我们的目的就是把它做成 BeautifulSoup(靓汤)。
知识点
- Requests
- BeautifulSoup
- 网络爬虫
- 循环
- 字典
- 列表
- 字符串方法
安装模块
首先我们安装 BeautifulSoup 模块,因为解析会用到 lxml 模块作为引擎,所以我们也一起安装。
xxxxxxxxxx11pip install bs4 lxml初识 BeautifulSoup
安装完成之后我们先通过一个小例子简单了解基本使用。打开 Python 解释器,运行下面的代码。
xxxxxxxxxx171from bs4 import BeautifulSoup2
3html_doc = """4<html><head><title>The Dormouse's story</title></head>5<body>6<p class="title"><b>The Dormouse's story</b></p>7
8<p class="story">Once upon a time there were three little sisters; and their names were9<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,10<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and11<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;12and they lived at the bottom of a well.</p>13
14<p class="story">...</p>15"""16
17soup = BeautifulSoup(html_doc, 'lxml') # 使用 lxml 解析器对网页字符串进行初始化基本的标签搜素
xxxxxxxxxx51soup # 可以返回初始化之后的网页2soup.find('p') # 返回第一个 p 标签3soup.p # 和 soup.find('p') 一样,返回第一个 p 标签4soup.find_all('p') # 以列表的形式返回所有 p 标签5soup('p') # 和 soup.find_all('p') 一样,以列表形式返回所有 p 标签运行效果如下:
标签文本的获取
xxxxxxxxxx31soup.text # 获取整个网页的文本2print(soup.text) # 通过 print 打印之后更直观3soup.p.text # 获取第一个 p 标签的文本运行效果如下:
标签属性值的获取
xxxxxxxxxx81# 获取第一个 a 标签的所有属性,以字典形式返回。2soup.a.attrs3# 获取第一个 a 标签的 href 值,其实是从字典中取值。4soup.a['href'] 5# 同上,获取第一个标签的 href 值,也是从字典中取值的方式。6soup.a.get('href') 7# 通过列表推导式获取所有 a 标签的 href 属性8[i.get('href') for i in soup('a')] 运行效果如下:
标签搜索的进阶
xxxxxxxxxx151 获取全部 a 标签和 b 标签,返回列表形式2soup.find_all(['a','b']) 3# 获取 class 值为 title 的 p 标签,class 需写做 class_。4soup.find_all('p',class_='title') 5# 同上,指定标签的时候,class_ 可省略。6soup.find_all('p','title')7# 获取全部 class 值为 sister 的标签8soup.find_all(class_='sister')9# 获取 id 为 link1 的标签10soup.find_all(id="link1")11# 下面几个是使用 css 选择器搜素标签12soup.select('title')13soup.select('body a')14soup.select("head > title")15soup.select("p > #link1")运行效果如下:
通过上面的学习,已经可以满足一般情况的网页文本提取,更进一步的学习可以通过阅读
实验总结
本节实验我们学习了 BeautifulSoup 的基本使用,BeautifulSoup 是一个强大的解析工具,可以很方便的从网页数据中抽取文本,一定要好好掌握。
提示
【试一试】爬取并解析网站
介绍
BeautifulSoup 是 Python 中一个很常用的模块,功能包括解析 HTML、XML 文档、修复含有未闭合标签错误的文档等。名字的由来是因为在网页开发中常把语法错误和用法混乱的标签称为 tag soup(大杂烩),我们的目的就是把它做成 BeautifulSoup(靓汤)。
目标
本次挑战,我们需要使用 Python 访问软科世界大学排行榜来获取首页 30 所学校的信息。
为避免目标网站的内容发生变化,我们使用保存之后的网页进行实验。
链接如下:
xxxxxxxxxx11https://labfile.oss.aliyuncs.com/courses/4070/rank2021.html 网页内容如图所示:
要求
- 脚本文件路径为
/home/project/rank2021.py。 - 目标网站为:
https://labfile.oss.aliyuncs.com/courses/4070/rank2021.html - 请安装
BeautifulSoup模块,确保脚本能够正常运行。 - 脚本需要实现对目标网站的抓取和解析,并打印输出。
- 输出共 30 行。
- 最终运行效果如下:
3.2 初识 Xpath
【练一练】初识 Xpath
实验介绍
XPath,全称 XML Path Language,中文翻译为 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。所以在做爬虫时我们经常使用 XPath 做相应的数据解析提取。
知识点
- xpath 介绍
- xpath 语法
- 手写 xpath
xpath 介绍
XPath,全称 XML Path Language,中文翻译为 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。所以在做爬虫时我们经常使用 XPath 做相应的数据解析提取。
xpath 使用路径表达式在 XML 文档中进行导航。也就是说,当我们用 xpath 进行定位的时候,代码会根据你写的 xpath 一层一层的进行定位。xpath 就像是一个地图,指引代码找到它的目标元素
XPath 语法
| 表达式 | 描述 |
|---|---|
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 匹配任何元素节点 |
根据上面的表格,我们分析一下这个 xpath://*[@id="header-navbar-collapses"]/ul[1]/li[3]/a
//即从当前选择的文档节点开始*匹配任何元素节点[@id="header-navbar-collapses"]通过id属性确认当前文档开始的节点位置,即从id为header-navbar-collapses的位置开始/这个斜杠没有打头,所以这里意思是下一级ul[1]这里方括号中的1表示第一个ul标签。注意:xpath 中的标签数从 1 开始li[3]表示第三个li标签
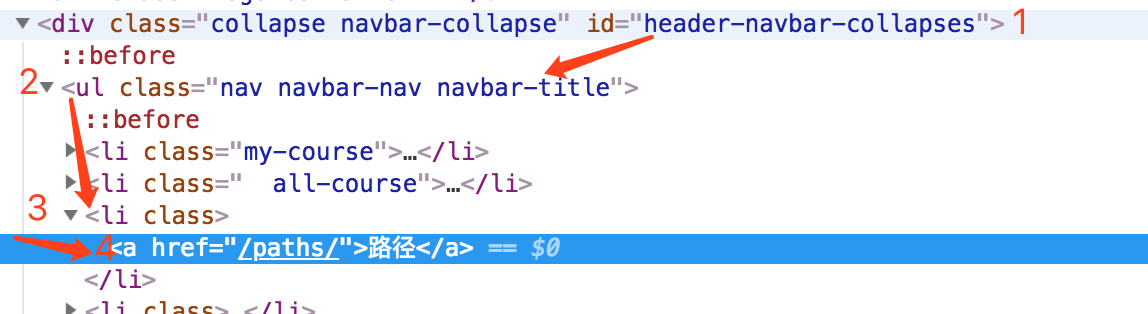
再举一个例子

现在来看“登录”的 xpath://*[@id="header-navbar-collapses"]/ul[2]/li[2]/a
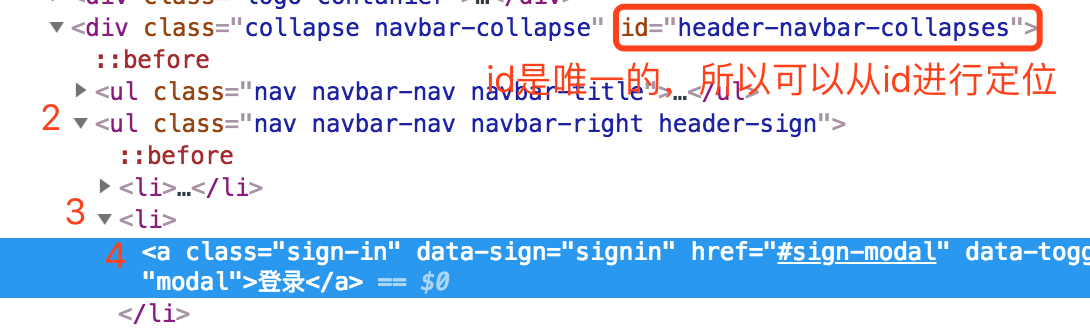
//即从当前选择的文档节点开始*匹配任何元素节点[@id="header-navbar-collapses"]通过id属性确认当前文档开始的节点位置/斜杠没有用作开头,所以这里是下一级的意思ul[2]定位到上面id属性下一层的第二个ul标签li[2]定位到ul下一层的第二个li标签a定位到li标签下一层的a标签
利用浏览器定位 xpath
我们使用浏览器新标签打开蓝桥云课 (https://www.lanqiao.cn) 网站。
现在要对“课程”按钮进行定位:
点击键盘的 F12,这时浏览器会弹出开发者工具:
最左侧的方框+小箭头叫做元素选择器。单击这个元素选择器以后,去页面点击想定位的元素“课程”:
此时定位到的标签,就是“路径”按钮对应的 HTML 标签了。然后将光标移动至该标签处,单击鼠标右键,选择复制,可以看到【复制 XPath】。另外还支持一些其他的选择器。
这里我们选择 XPath,然后在文本编辑器里就可以粘贴复制的 XPath 了:
xxxxxxxxxx11//*[@id="__layout"]/div/div[1]/div[2]/ul/li[1]/div[1]/a/span
随着网站更新,复制出来的 Xpath 可能会有不同,只要能实现定位就都是可以的
手写 XPath
有时候我们从浏览器复制出来的 xpath 并不能定位到我们想要的元素,原因在于有一些网站的id元素属性也是变化的。这时候我们就只能自己来写 xpath 了。
例子一

我们来定位“实验楼”这个图片元素的 xpath,看到的 HTML 文档结构如下图:
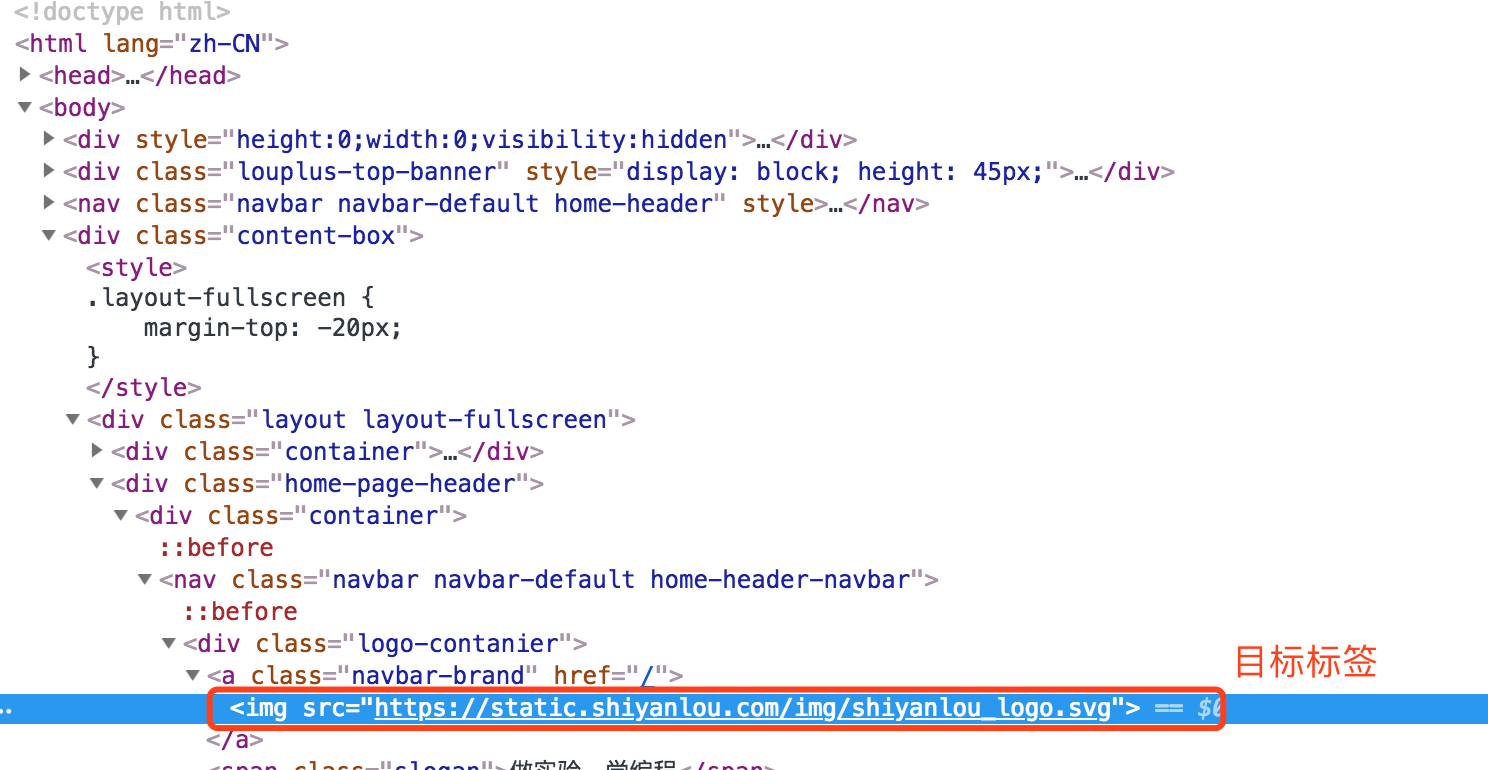
分析:
- 目标元素是
img标签 - 从
img标签往上查找文档,看有没有唯一的属性值,如id。注意,class属性值一般不是唯一的,所以一般不用class属性作为定位元素 - 发现文档中直到文档顶部也没有属性唯一的元素,所以这里我们就从文档顶部即根节点开始
/的意思即从根节点选取- 所以我们可以确定 xpath 开头是
/ - 第一层是
html标签,所以 xpath 初步确定为/html - 第二层是
body标签,xpath 确定为/html/body - 目标元素在
body标签下第三个div中,所以 xpath 确定为/html/body/div[3] - 下一层只有一个
div标签,这是可以省略后面的[1],即/html/body/div[3]/div - 再下一层在第二个
div中,所以 xpath 确定为/html/body/div[3]/div/div[2] - 依次类推,继续向下一层定位,即可确定 xpath 为
/html/body/div[3]/div/div[2]/div/nav/div[1]/a/img
例子二
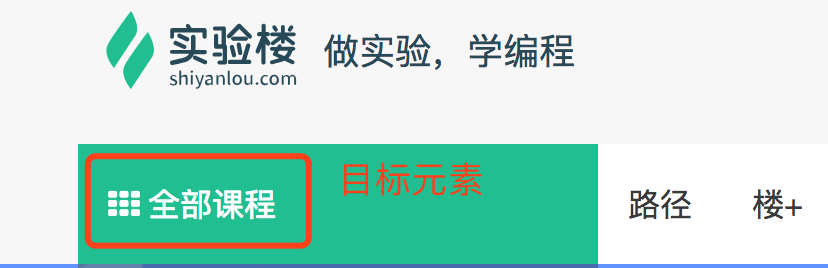
我们来定位搜索框的 xpath,看到的 HTML 文档结构如下图:

分析:
- 目标元素是
a标签 - 从目标元素开始往上查找属性唯一的元素
- 发现有
id属性,且该属性值固定不变,所以可以直接利用id属性进行定位 //即从当前选择的文档节点开始,即//*[@id='header-navbar-collapses']- 下一层
ul不唯一,所以 xpath 里要写索引,即//*[@id="header-navbar-collapses"]/ul[1] - 接下来的
li标签也不是唯一的,所以 xpath 确定为//*[@id="header-navbar-collapses"]/ul[1]/li[1] - 最后定位到
a标签,所以确定 xpath 为//*[@id="header-navbar-collapses"]/ul[1]/li[1]/a
实验总结
本次实验我们介绍了如何通过浏览器插件获取元素的 xpath,以及如何根据 HTML 文档手写 xpath,这样在定位元素的时候就会方便很多
3.3 Xpath 获取节点对象
【练一练】Xpath 获取节点对象
实验介绍
前面的实验中,我们初步认识了 Xpath 的语法。本节实验,我们将使用 Python 语言,通过 Xpath 获取标签节点对象。
知识点
- lxml 安装
- etree 模块
- Xpath 语法
- 获取全部节点
- 获取子节点
- 获取父节点
- 通过属性获取节点
安装 lxml 模块
Python 中,我们主要使用 lxml 库的 etree 模块使用 Xpath 语法进行网页数据的解析。在使用之前,需要先安装 lxml 模块。
xxxxxxxxxx11pip install lxml目标网站
本节我们以 https://labfile.oss.aliyuncs.com/courses/10828/xpath.html 作为目标网站进行实验。
首先,我们在 /home/project 目录下新建 xdemo1.py 文件,写入下面内容。
xxxxxxxxxx51import requests2
3url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'4res = requests.get(url).text5print(res)运行效果如下:
学习过 requests 模块,这段代码应该非常容易理解。我们使用 requests 模块获取了网页的源码
etree 模块的 HTML 方法
接下来,我们学习 etree 模块的 HTML 方法,该方法需要我们传入一个字符串类型的 HTML 文档,也就是我们前面通过 requests 获取到的内容。返回值是 HTML 文档的根节点。
在 /home/project 目录下新建 xdemo2.py 文件,写入下面代码。
xxxxxxxxxx71from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7print(html)运行效果如下:
获取所有节点
接下来,我们使用 Xpath 来获取我们想要的数据。
首先用 XPath 规则来获取所有的节点。其中 * 代表匹配所有节点,返回的结果是一个列表,每个元素都是一个 Element 类型,后跟节点名称。
目标网站的源代码如下,我们可以对照着学习。
在 /home/project 目录下新建 xdemo3.py 文件,写入下面代码。
xxxxxxxxxx81from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//*')8print(result)运行效果如下:
我们也可以指定匹配的节点名称,比如获取全部的 <li> 标签。
目标网站的源代码如下,我们可以对照着学习。
在 /home/project 目录下新建 xdemo4.py 文件,写入下面代码。
xxxxxxxxxx81from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//li')8print(result)运行效果如下:
获取子节点
通过 / 查找元素的子节点或子孙节点。比如我们选择 <li> 节点的所有直接 <a> 子节点。
目标网站的源代码如下,我们可以对照着学习。
在 /home/project 目录下新建 xdemo5.py 文件,写入下面代码。
xxxxxxxxxx81from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//li/a')8print(result)运行效果如下:
属性匹配节点
匹配时可以用 @ 符号进行属性过滤。
目标网站的源代码如下,我们可以对照着学习。
在 /home/project 目录下新建 xdemo6.py 文件,写入下面代码。
xxxxxxxxxx81from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//li[@class="item-inactive"]')8print(result)运行效果如下:
代码中,我们通过限定 class 值精准的获取了对应的标签节点
通过子节点获取父节点
方法一
通过子节点获取父节点,我们可以像目录结构一样用 .. 来实现。
目标网站的源代码如下,我们可以对照着学习。
在 /home/project 目录下新建 xdemo7.py 文件,写入下面代码。
xxxxxxxxxx81from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//a[@href="link4.html"]/..')8print(result)运行效果如下:
本例中,我们先通过 @href 的方式获取了 <a> 标签,然后获取了它的父节点 <li>,然后获取了这个父标签的 class 的属性值。
方法二
除了使用 .. 的方式获取,我们还可以通过 /parent::* 的方式获取父节点。
在 /home/project 目录下新建 xdemo8.py 文件,写入下面代码。
xxxxxxxxxx81from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//a[@href="link4.html"]/parent::*')8print(result)运行效果如下:
实验总结
本节实验,我们通过 lxml 库中的 etree 模块使用 Xpath 语法获取了标签节点对象,包括获取全部节点、获取子节点、获取父节点、通过属性获取节点等。
3.4 Xpath 获取文本数据
【练一练】Xpath 获取文本数据
实验介绍
前面的例子中,我们大部分都是只获取到了节点对象。我们通常主要是获取网站的节点的特定文本和属性值,本节我们将学习获取文本数据。
知识点
- Xpath 语法
- 获取文本数据
目标网站
目标网站为 https://labfile.oss.aliyuncs.com/courses/10828/xpath.html。
目标网站的源代码如下,我们可以对照着学习。
通过 /text() 获取文本内容
通过 /text() 获取指定标签下的文本内容。
首先,我们在 /home/project 目录下新建 xdemo9.py 文件,写入下面内容。
xxxxxxxxxx81from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//li[@class="item-0"]/a/text()')8print(result)运行效果如下:
通过 //text() 获取所有文本内容
通过 //text() 可以获取指定标签下的所有文本内容,包括子标签下的文本内容,但这种方式可能会导致数据中混入很多换行符和空格。
首先,我们在 /home/project 目录下新建 xdemo10.py 文件,写入下面内容。
xxxxxxxxxx81from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//li[@class="item-0"]//text()')8print(result)运行效果如下:
可以看到,除了我们需要的 <a> 标签的文本之外,还混入了回车和空格
节点对象的 text 属性
我们也可以在获取到节点对象之后再通过内置的 text 属性获取节点的文本数据。
首先,我们在 /home/project 目录下新建 xdemo11.py 文件,写入下面内容。
xxxxxxxxxx91from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//li[@class="item-0"]/a')8for i in result:9 print(i.text)运行效果如下:
因为 result 返回值是一个列表,所以我们通过循环获取了每一项的 text 属性
实验总结
本节实验,我们学习了通过 Xpath 方式提取节点的文本数据,既有纯 Xpath 规则,也有混合 lxml 内置方法的操作,实践中可以根据具体情况灵活使用
3.5 Xpath 获取属性值
【练一练】Xpath 获取属性值
实验介绍
前面的例子中,我们介绍了获取节点对象和节点的文本数据,有时候我们还需要获取一些属性值,比如一些标签的 class 值、<a> 标签的 href 值等。
知识点
- Xpath 语法
- 获取属性值
目标网站
目标网站为 https://labfile.oss.aliyuncs.com/courses/10828/xpath.html。
目标网站的源代码如下,我们可以对照着学习。
Xpath 获取 href 属性
在 XPath 语法中,我们可以通过 @ 符号直接获取节点的属性值。
首先,我们在 /home/project 目录下新建 xdemo12.py 文件,写入下面内容。
xxxxxxxxxx81from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//li/a/@href')8print(result)运行效果如下:
这里我们获取了 <li> 标签下的 <a> 标签的 href 属性
Xpath 获取 class 属性
接下来,我们来获取 class 属性的值。
首先,我们在 /home/project 目录下新建 xdemo13.py 文件,写入下面内容。
xxxxxxxxxx81from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//a[@href="link4.html"]/../@class')8print(result)运行效果如下:
这里我们首先获取了 href 属性为 "link4.html" 的 <a> 标签,然后获取了它的父对象的 class 属性的值
通过对象方法获取属性值
和获取文本数据一样,属性值也可以通过对象的内置方法来获取。
首先,我们在 /home/project 目录下新建 xdemo14.py 文件,写入下面内容。
xxxxxxxxxx91from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//a[@href="link4.html"]/..')8for i in result:9 print(i.get('class'))运行效果如下:
这里我们首先获取了 href 属性为 "link4.html" 的 <a> 标签的父对象,然后通过循环获取列表中每一个对象的 class 属性。获取的是时候使用 get 方法进行实现
实验总结
本节实验,我们学习了使用 Xpath 获取节点的属性值,包括使用 Xpath 规则和配合对象内置的 get 方法,具体实践中可以根据实际情况配合操作
3.6 Xpath 更多节点选择
【练一练】Xpath 更多节点选择
实验介绍
前面我们介绍了基本的节点选择方式,本节我们将学习按序选择节点和节点轴选择。
知识点
- 按序选择
- 节点轴选择
目标网站
目标网站为 https://labfile.oss.aliyuncs.com/courses/10828/xpath.html。
目标网站的源代码如下,我们可以对照着学习。
按序选择
有时候我们在匹配到的多个节点中选择第一个或最后一个,这时候可以通过中括号内加索引。需要注意的是 Xpath 语法中索引是从 1 开始的;最后一个元素不能使用 -1,可以使用 last()。
首先,我们在 /home/project 目录下新建 xdemo15.py 文件,写入下面内容。
xxxxxxxxxx141from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//li[1]/a/text()')8print('第一个:', result)9result = html.xpath('//li[last()]/a/text()')10print('最后一个:', result)11result = html.xpath('//li[last()-1]/a/text()')12print('倒数第二个:', result)13result = html.xpath('//li[position()<3]/a/text()')14print('前两个:', result)运行效果如下:
节点轴选择
XPath 还提供了很多节点轴选择方法,包括子元素、兄弟元素、父元素、祖先元素等,我们在前面介绍父元素的时候曾经有提到。
首先,我们在 /home/project 目录下新建 xdemo16.py 文件,写入下面内容。
xxxxxxxxxx161from lxml import etree2import requests3
4url = 'https://labfile.oss.aliyuncs.com/courses/10828/xpath.html'5res = requests.get(url).text6html = etree.HTML(res)7result = html.xpath('//li[1]/ancestor::*')8print('当前节点的所有祖先节点:', result)9result = html.xpath('//li[1]/attribute::*')10print('当前节点所有属性值:', result)11result = html.xpath('//li[1]/child::*')12print('当前节点的直接子节点:', result)13result = html.xpath('//li[1]/descendant::a')14print('当前节点所有子孙 a 节点:', result)15result = html.xpath('//li[1]/following::*[2]')16print('当前所有节点之后的第二个节点:', result)运行效果如下:
我们只举例说明了一些常用的,更多的轴语法可以参考 Xpath 轴语法
实验总结
本节我们学习了 Xpath 节点的排序选择和轴语法,在实际使用中我们会混合使用多种语法,可以尝试多种方式的排列组合实践