第七章Scrapy爬虫
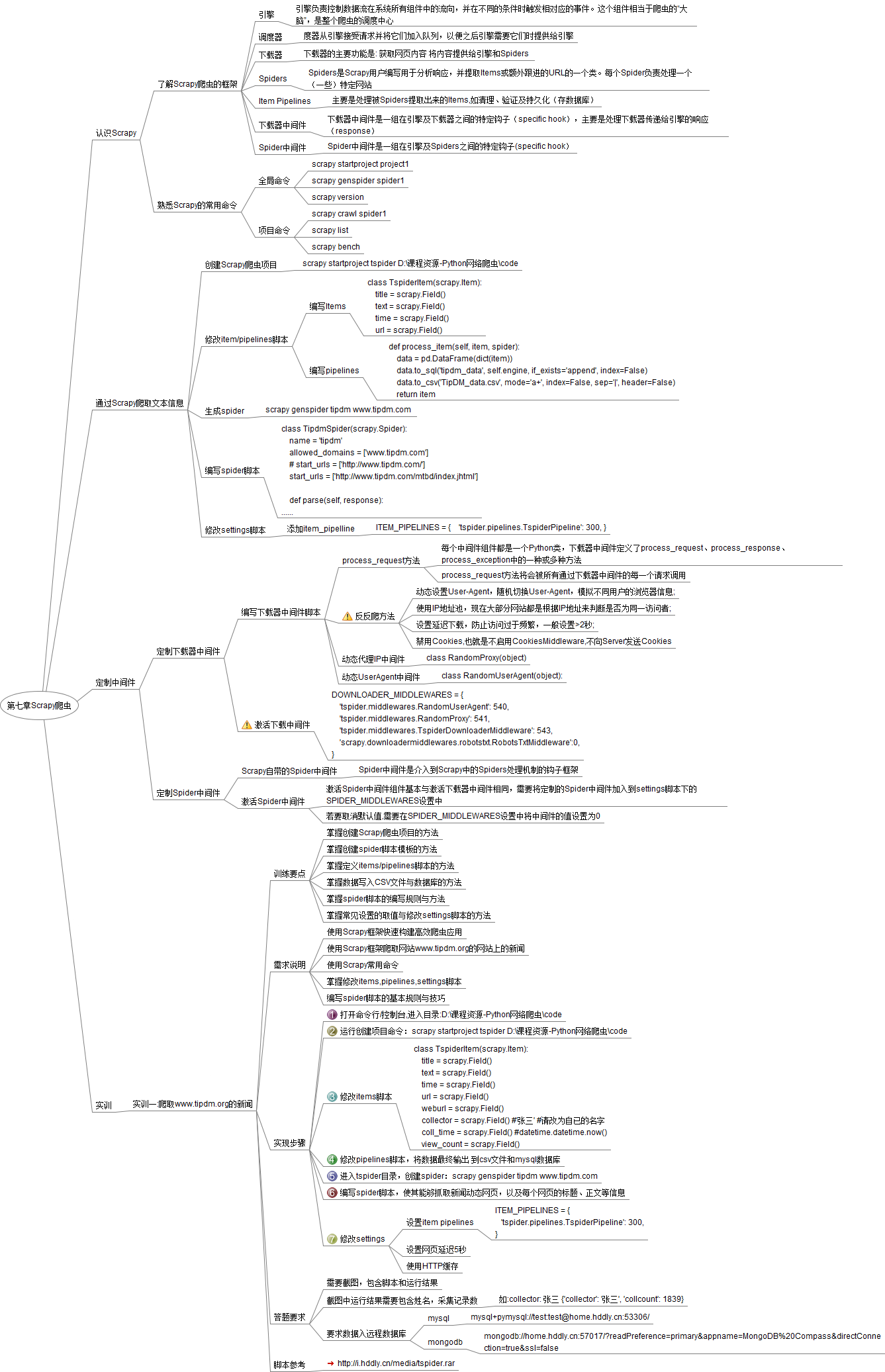
第七章Scrapy爬虫
认识Scrapy
了解Scrapy爬虫的框架
引擎
引擎负责控制数据流在系统所有组件中的流向,并在不同的条件时触发相对应的事件。这个组件相当于爬虫的“大脑”,是整个爬虫的调度中心
调度器
度器从引擎接受请求并将它们加入队列,以便之后引擎需要它们时提供给引擎
下载器
下载器的主要功能是: 获取网页内容 将内容提供给引擎和Spiders
Spiders
Spiders是Scrapy用户编写用于分析响应,并提取Items或额外跟进的URL的一个类。每个Spider负责处理一个(一些)特定网站
Item Pipelines
主要是处理被Spiders提取出来的Items,如清理、验证及持久化(存数据库)
下载器中间件
下载器中间件是一组在引擎及下载器之间的特定钩子(specific hook),主要是处理下载器传递给引擎的响应(response)
Spider中间件
Spider中间件是一组在引擎及Spiders之间的特定钩子(specific hook)
熟悉Scrapy的常用命令
全局命令
scrapy startproject project1
scrapy genspider spider1
scrapy version
项目命令
scrapy crawl spider1
scrapy list
scrapy bench
通过Scrapy爬取文本信息
创建Scrapy爬虫项目
scrapy startproject tspider D:\课程资源-Python网络爬虫\code
修改item/pipelines脚本
编写Items
class TspiderItem(scrapy.Item):
title = scrapy.Field()
text = scrapy.Field()
time = scrapy.Field()
url = scrapy.Field()
编写pipelines
def process_item(self, item, spider):
data = pd.DataFrame(dict(item))
data.to_sql('tipdm_data', self.engine, if_exists='append', index=False)
data.to_csv('TipDM_data.csv', mode='a+', index=False, sep='|', header=False)
return item
生成spider
scrapy genspider tipdm www.tipdm.com
编写spider脚本
class TipdmSpider(scrapy.Spider):
name = 'tipdm'
allowed_domains = ['www.tipdm.com']
# start_urls = ['http://www.tipdm.com/']
start_urls = ['http://www.tipdm.com/mtbd/index.jhtml']
def parse(self, response):
......
修改settings脚本
添加item_pipelline
ITEM_PIPELINES = { 'tspider.pipelines.TspiderPipeline': 300, }
定制中间件
定制下载器中间件
编写下载器中间件脚本
process_request方法
每个中间件组件都是一个Python类,下载器中间件定义了process_request、process_response、process_exception中的一种或多种方法
process_request方法将会被所有通过下载器中间件的每一个请求调用
反反爬方法
动态设置User-Agent,随机切换User-Agent,模拟不同用户的浏览器信息;
使用IP地址池,现在大部分网站都是根据IP地址来判断是否为同一访问者;
设置延迟下载,防止访问过于频繁,一般设置>2秒;
禁用Cookies,也就是不启用CookiesMiddleware,不向Server发送Cookies
动态代理IP中间件
class RandomProxy(object)
动态UserAgent中间件
class RandomUserAgent(object):
激活下载中间件
DOWNLOADER_MIDDLEWARES = {
'tspider.middlewares.RandomUserAgent': 540,
'tspider.middlewares.RandomProxy': 541,
'tspider.middlewares.TspiderDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware':0,
}
定制Spider中间件
Scrapy自带的Spider中间件
Spider中间件是介入到Scrapy中的Spiders处理机制的钩子框架
激活Spider中间件
激活Spider中间件组件基本与激活下载器中间件相同,需要将定制的Spider中间件加入到settings脚本下的SPIDER_MIDDLEWARES设置中
若要取消默认值,需要在SPIDER_MIDDLEWARES设置中将中间件的值设置为0
实训
实训一:爬取www.tipdm.org的新闻
训练要点
掌握创建Scrapy爬虫项目的方法
掌握创建spider脚本模板的方法
掌握定义items/pipelines脚本的方法
掌握数据写入CSV文件与数据库的方法
掌握spider脚本的编写规则与方法
掌握常见设置的取值与修改settings脚本的方法
需求说明
使用Scrapy框架快速构建高效爬虫应用
使用Scrapy框架爬取网站www.tipdm.org的网站上的新闻
使用Scrapy常用命令
掌握修改items,pipelines,settings脚本
编写spider脚本的基本规则与技巧
实现步骤
打开命令行/控制台,进入目录:D:\课程资源-Python网络爬虫\code
运行创建项目命令:scrapy startproject tspider D:\课程资源-Python网络爬虫\code
修改items脚本
class TspiderItem(scrapy.Item):
title = scrapy.Field()
text = scrapy.Field()
time = scrapy.Field()
url = scrapy.Field()
weburl = scrapy.Field()
collector = scrapy.Field() #'张三' #请改为自已的名字
coll_time = scrapy.Field() #datetime.datetime.now()
view_count = scrapy.Field()
修改pipelines脚本,将数据最终输出 到csv文件和mysql数据库
进入tspider目录,创建spider:scrapy genspider tipdm www.tipdm.com
编写spider脚本,使其能够抓取新闻动态网页,以及每个网页的标题、正文等信息
修改settings
设置item pipelines
ITEM_PIPELINES = {
'tspider.pipelines.TspiderPipeline': 300,
}
设置网页延迟5秒
使用HTTP缓存
答题要求
需要截图,包含脚本和运行结果
截图中运行结果需要包含姓名,采集记录数
如:collector: 张三 {'collector': '张三', 'collcount': 1839}
要求数据入远程数据库
mysql
mysql+pymysql://test:test@home.hddly.cn:53306/
mongodb
mongodb://home.hddly.cn:57017/?readPreference=primary&appname=MongoDB%20Compass&directConnection=true&ssl=false
脚本参考
http://i.hddly.cn/media/tspider.rar